9.2. S4: desenvolvimento integrado de documentos
Apesar de ter sido um passo em frente na caótica produção documental, o SGML não é de todo acessível ao utilizador comum. Quando, numa determinada linha administrativa, se faz a opção de produzir toda a documentação em SGML, algum cuidado deve ser colocado na adaptação dos utilizadores a esta nova maneira de "pensar" e "produzir" documentos. Esta foi uma das preocupações que esteve na génese do S4. A constatação do que se passa com as páginas HTML veio também reforçar a ideia de criar o S4: não é preciso ser-se um utilizador muito experiente para conseguir produzir documentos para disponibilizar no "World Wide Web (WWW)"; muita gente, nas mais variadas áreas profissionais, produz páginas HTML; na maior parte das vezes, estes utilizadores não têm consciência de que aquilo que estão a fazer é escrever um documento SGML de acordo com um DTD - o DTD do HTML. É, precisamente, esta transparência e simplicidade de utilização que interessa captar para o sistema S4.
O nome S4 vem do inglês "Syntax, Semantics and Style Specification".
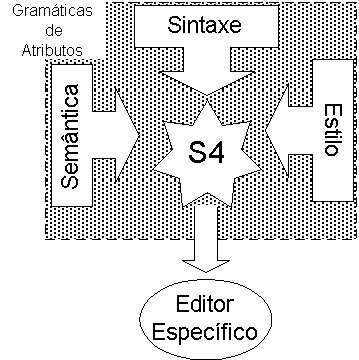
Na sequência do trabalho e dos assuntos abordados no decorrer desta dissertação surgiu o S4. A ideia, esquematizada na Figura 9-1, é integrar as três grandes linhas da edição estruturada de documentos: a sintaxe, a semântica e o estilo.
No fim, o sistema resultante será capaz de gerar editores estruturados WYSIWYG sensíveis a restrições semânticas. O ponto comum, o chapéu de que se falava há pouco, é um sistema gerador de compiladores baseado em gramáticas de atributos; inicialmente começou por ser o "Synthesizer Generator" [RT89a, RT89b], mas, a breve prazo, será iniciado um projecto de implementação em LRC [SAS99,Sar99] ou ANTLR [ANTLR] - o objectivo é encontrar o ambiente que forneça melhor qualidade no produto final, principalmente, maior capacidade de portabilidade nos editores gerados, pois neste aspecto, o SGen é bastante limitado mas o LRC e o ANTLR apesar de serem menos limitados perdem algumas características de qualidade que o outro tem. De realçar, no entanto, que, enquanto o LRC está ao nível do SGen, estando a diferença patente nalguns pormenores, o mesmo não se passa com o ANTLR, principalmente ao nível da geração de interfaces finais que o ANTLR não suporta.
Na próxima secção (Secção 9.2.1), descreve-se a arquitectura funcional do sistema, do ponto de vista do utilizador e do analista, antes de se apresentar a descrição do interior do sistema. Noutra secção (Secção 9.2.5), descreve-se o suporte da linguagem de restrições, um dos contributos específicos desta dissertação. Por fim, mostra-se a aplicação da linguagem aos problemas dos casos de estudo levantados ao longo da dissertação.
9.2.1. Arquitectura do sistema S4
Na Figura 9-2, apresenta-se a arquitectura básica de utilização do sistema.
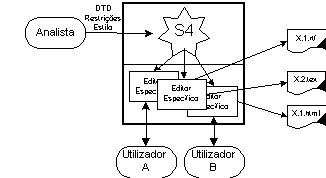
O sistema disponibiliza duas interfaces diferentes: uma para o utilizador e outra para o analista. O objectivo é conseguir um sistema integrado com dois níveis de acesso diferentes. Um de carácter administrativo e outro de utilização.
A interface disponibilizada ao analista permite-lhe definir novos tipos de documento: qual a sua estrutura, quais os invariantes sobre o seu conteúdo que deverão ser verificados e qual a aparência/estilo (uma ou mais) final dos documentos desse tipo.
O utilizador apenas se servirá do sistema para produzir os seus documentos. Por isso, apenas lhe é permitida a escolha de um tipo de documento e, dentro dos estilos disponíveis para esse tipo, qual o pretendido.
As próximas figuras servem para apresentar a arquitectura do S4. A apresentação encontra-se dividida em quatro partes porque fazê-la de uma só vez e recorrendo a uma só figura torná-la-ia complexa e conduziria à perda de algum pormenor.
Na figura seguinte apresentam-se os principais blocos do sistema e respectivas interdependências:
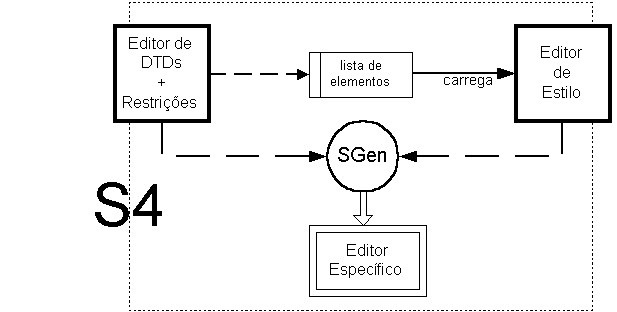
No S4, os pontos de interacção com o utilizador são os três editores representados na Figura 9-3: o editor de DTDs, o editor de Estilo e o editor Específico (que representa um qualquer editor dos que irão ser gerados pelo editor.
O editor de DTDs e o editor de Estilo são ambos gerados pelo SGen e ambos os editores vão fornecer parte da especificação de cada um dos editores específicos que serão gerados. O editor de DTDs foi especificado e implementado no decurso de uma tese de mestrado [Lop98] mas a geração da especificação para os novos editores ainda está a ser trabalhada. O editor de Estilo foi desenvolvido no decurso de outra tese de mestrado [Sou98] mas a sua interacção com o editor de DTDs só recentemente ficou estabelecida.
Assim, o analista que utiliza o S4 tem à sua disposição dois editores, de certa forma interligados:
um editor sensível à sintaxe do SGML que foi enriquecido com sintaxe extra de modo a permitir especificar restrições;
e outro que é sensível a uma sintaxe muito semelhante à linguagem "eXtended Style Language" (XSL - [XSL]).
O primeiro serve para o analista especificar o DTD e as restrições semânticas e o segundo para especificar o estilo, o aspecto visual final a associar a cada elemento.
O editor de DTDs é genérico, conhece a sintaxe SGML e permite ao analista especificar qualquer DTD. Conhece também a sintaxe da linguagem de restrições, que é especificada mais à frente, e permite ao analista a introdução de restrições.
O editor de estilos é também genérico, neste momento, suporta um subconjunto da sintaxe do XSL. Há, no entanto, uma pequena dependência entre este e o editor de DTDs. A ideia por detrás desta dependência é a de que, conhecendo a estrutura de um determinado tipo de documentos (DTD), a especificação de estilo será restrita aos elementos presentes nessa estrutura. Assim, pode-se gerar um esqueleto da especificação de estilo automaticamente partindo do DTD, com a dupla vantagem de nenhum elemento ter sido esquecido, nem ser necessário ter presente todos os elementos. Isso é conseguido através de uma funcionalidade acrescentada ao editor de estilos: no início, este cria o seu estado inicial baseando-se no conteúdo de um ficheiro gerado pelo editor de DTDs com informação sobre os elementos presentes no DTD em causa.
Alguns dos operadores do SGML e algumas das suas facilidades[1] fazem com que algumas das linguagens definidas por DTDs não sejam regulares [Bru94]. Sem esses operadores e facilidades, um DTD é comparável a uma gramática independente de contexto. Como a razão entre a sua utilidade[2] e o custo da sua implementação é muito baixa, esses operadores e facilidades não são suportados pelo editor de DTDs. A gramática abstracta, representada na sintaxe SSL, é o resultado mais relevante do editor de DTDs.
Recebendo estas especificações (DTD, restrições, especificação de estilo) o S4 vai usar uma instância do SGen para processá-las e produzir um novo editor estruturado. Este editor é específico e permitirá ao utilizador escrever documentos de um determinado tipo.
A filosofia e a integração destes editores estão relacionadas com a metodologia e a ferramenta que se estão a utilizar. Um editor estruturado gerado pelo SGen, ou pelo LRC, é composto por dois blocos funcionais: um faz o reconhecimento sintático e semântico e como resultado produz uma representação intermédia (uma árvore de sintaxe abstracta decorada); o outro realiza uma tarefa de síntese, faz uma travessia à representação intermédia e gera normalmente uma visão transformada dos dados da árvore.
Na figura seguinte, apresenta-se este esquema.
Figura 9-4. Arquitectura funcional de um editor estruturado
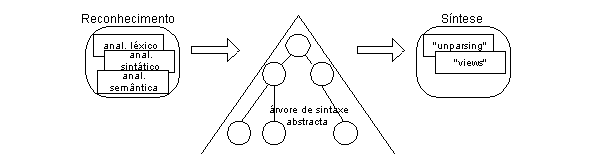
O reconhecimento é essencialmente especificado pela gramática de atributos da linguagem que se está a reconhecer e usa equações sobre os atributos da gramática para construir a representação intermédia. A síntese é essencialmente especificada pelas "unparsing rules", que também podem recorrer a equações sobre atributos para transformar parte da informação.
O cerne do S4, o editor de DTDs com restrições, foi também gerado da mesma maneira que os novos editores: especificou-se em SSL o SGML, adicionou-se a especificação da sub-linguagem de restrições e utilizou-se o SGen para compilar tudo e gerar o editor final. Como explicado acima, idêntica abordagem é usada para produzir o editor de estilos. Desta maneira, o S4 encontra-se implementado usando uma filosofia de "bootstrap".
Para clarificar melhor alguns aspectos funcionais desta arquitectura apresentam-se nas secções seguintes cada um destes editores.
9.2.2. Editor de DTDs
O editor de DTDs, na sua primeira versão, foi objecto de estudo de um projecto de investigação (DAVID - especificação e processamento algébrico de documentos, [HAR99]) e de uma tese de mestrado [Lop98].
Na figura seguinte, pode ver-se um esquema da interacção deste editor com os outros blocos funcionais do sistema:
Figura 9-5. Editor de DTDs
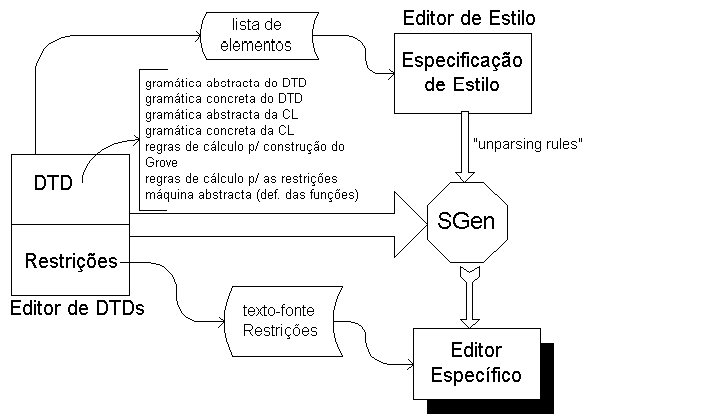
As tarefas realizadas por este editor podem sumarizar-se na seguinte lista:
O editor permite ao analista uma edição assistida do DTD e respectivas restrições
Gera a gramática abstracta correspondente ao DTD introduzido.
Gera, também, a respectiva sintaxe concreta para que o novo editor específico além de criar também possa carregar documentos já existentes e editá-los.
Como se verá à frente em mais detalhe, as restrições actuam sobre a instância documental pelo que o seu processamento está dependente da instância que será introduzida pelo utilizador. Isto faz com que o processamento das restrições tenha que ser realizado no editor específico. Para esse efeito, a especificação dos novos editores é enriquecida com a gramática abstracta e com a gramática concreta da linguagem de especificação das restrições -- CL. Além disso, o editor de DTDs também coloca o texto fonte das restrições num ficheiro externo que será depois carregado pelo editor específico.
O processamento das restrições, especificado mais à frente, trabalha sobre uma representação intermédia da instância documental -- o Grove. Para possibilitar isto, o editor de DTDs gera também um conjunto de regras de cálculo para a construção desta representação intermédia.
O processamento das restrições é realizado através de uma máquina abstracta que trabalha sobre a representação intermédia. A definição das funções que implementam esta máquina abstracta é também gerada pelo editor de DTDs e acrescentada à especificação do editor específico.
Por fim, as regras de cálculo associadas às restrições e que vão permitir a sua tradução em instruções da máquina abstracta são também geradas por este editor e adicionadas à especificação do editor específico.
A máquina abstracta pode ser sintetizada no seguinte esquema:
Figura 9-6. Máquina Abstracta
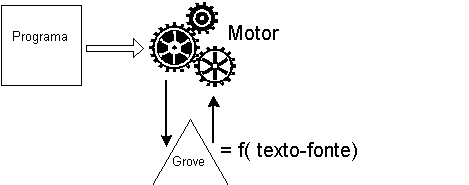
O SGen junta todas estas componentes geradas pelo editor de DTDs com a componente gerada pelo editor de estilo e gera um editor específico.
A tarefa central do editor de DTDs é a conversão de um DTD para uma gramática abstracta. Como já foi discutido, procurou-se automatizar este processo. A automatização foi conseguida graças à elaboração de um conjunto de regras que no seu todo formam o algoritmo de conversão. No Apêndice C, encontram-se descritas todas as regras que se sumarizam abaixo, pois serão importantes nas discussões que se seguirão:
- Elemento do DTD → Símbolo não-terminal da gramática abstracta
Para cada elemento do DTD é gerado um símbolo não-terminal da gramática. O conjunto de produções deste símbolo permite derivar o conteúdo associado a este elemento. Estas produções são geradas num ou mais passos conforme a expressão de conteúdo do elemento: de notar que no DTD existem operadores de ocorrência que não têm equivalência na notação gramatical (há notações gramaticais com BNF estendido [ANTLR], mas o SSL não pertence a esta categoria); a conversão consegue fazer-se usando a técnica de conversão de expressões regulares em gramáticas regulares (desde que algumas facilidades do SGML, que podem originar linguagens ambíguas ou não-regulares, não estejam presentes; são exemplos dessas facilidades o operador &, as inclusões e as exclusões; nestes casos algoritmos específicos teriam de ser utilizados mas nem todas as situações poderiam ser resolvidas - [Bru94]).
- Atributo de um Elemento do DTD → Símbolo não-terminal da gramática abstracta
Neste ponto e logo à partida, há um conflito de nomes que é necessário esclarecer: o atributo de um elemento de um DTD é diferente do atributo de um símbolo de uma gramática de atributos. O primeiro é um subelemento estrutural do elemento a que pertence e o segundo é utilizado para associar informação semântica a um símbolo. Pode-se ver isto ainda da seguinte maneira, em SGML há dois níveis de especificação estrutural, o elemento e o atributo, nas gramáticas há apenas um nível, o símbolo. A existência destes dois níveis em SGML tem sido alvo de muitas discussões (Secção 5.1.6) e, muito recentemente, tem até sido posta em causa (Secção D.7) -- o mais recente movimento a favor de uma "Simplified Markup Language - SML" defende, entre outras coisas a eliminação de atributos mediante a unificação destes com os elementos.
A solução para a eliminação dos atributos do SGML passa pela promoção daqueles a elementos (quem está habituado a usar SGML irá sempre arguir que algo se perdeu). Uma vez que nas gramáticas se tem apenas um nível de especificação estrutural, para converter DTDs em gramáticas tem-se que colocar atributos e elementos no mesmo plano. Assim, atributo e elemento serão tratados da mesma maneira e um atributo, tal como o elemento corresponderá a um símbolo não-terminal.
Como há vários tipos de atributo, cada um com a sua semântica específica, aqui as suas derivações também serão diferentes: um atributo do tipo enumerado corresponderá a um símbolo não-terminal com uma produção para cada um dos possíveis valores; um atributo com valor por omissão #IMPLIED terá duas produções, uma vazia e outra para o respectivo valor; um atributo com valor por omissão #REQUIRED será representado directamente pelo seu valor; ...
- Entidade do DTD → Símbolo não-terminal da gramática abstracta
No caso das entidades, guarda-se o seu identificador e os seus atributos num atributo da gramática que implementa uma tabela de símbolos convencional [PP92] e que será associado aos vários símbolos gramaticais (gerados pelas regras anteriores).
O principal efeito da declaração de uma entidade faz-se sentir nos elementos textuais, pois aquelas podem aparecer em qualquer ponto do texto. Assim, a derivação de um elemento de conteúdo textual tem que contemplar a possibilidade de no meio do texto aparecerem referências a entidades.
As restrições a associar ao DTD e a linguagem usada para as especificar serão tratadas à frente numa secção inteiramente dedicada a isso (Secção 9.2.5).
A seguir, apresenta-se um exemplo da conversão de um DTD pertencente a um caso de estudo:
Exemplo 9-2. Um sistema noticioso automático
Este exemplo foi extraído de uma aplicação real desenvolvida no âmbito do projecto GEiRA [GEIRA]. Neste exercício, utilizou-se um servidor de email especial para implementar um serviço noticioso automático. Qualquer pessoa que queira reportar um facto, um evento, ..., envia uma mensagem de email que tem de obedecer a uma certa estrutura. Esta mensagem é processada pelo servidor e se tudo estiver correcto a mensagem é publicada numa página WWW que actua como um boletim noticioso.
A estrutura da mensagem é definida pelo DTD que se apresenta a seguir:
<!DOCTYPE News [
<!-- root element News has title, begin-date, an optional
end-date and an optional body -->
<!-- it also has two required attributes: type and subject -->
<!ELEMENT News - - (Title, Begin-date, End-date?, Body?)>
<!ATTLIST News Type (Event | Novelty) #REQUIRED
Subject (Nature | Culture | Science) #REQUIRED>
<!ELEMENT Title - - (#PCDATA)>
<!ELEMENT Begin-date - - (#PCDATA)>
<!ELEMENT End-date - - (#PCDATA)>
<!ELEMENT Body - - (Para)+>
<!ELEMENT Para - - (#PCDATA)>
]>De acordo com os requisitos do sistema, uma mensagem que fosse enviada para este sistema, para ser tomada como válida, teria que respeitar o DTD e as seguintes restrições semânticas:
As notícias do tipo Event têm de ter uma Begin-date (já exigida pelo DTD) e uma End-date.
A End-date de uma notícia do tipo Event deverá sempre ser maior ou igual que a Begin-date dessa notícia.
Estas restrições serão especificadas na secção final (Secção 9.2.5.4) utilizando a linguagem para especificação de restrições que entretanto será definida.
Aplicando as regras brevemente enunciadas no início desta secção e detalhadas no Apêndice C, converte-se este DTD na Gramática independente de contexto que se segue:
News → NewsAttList NewsContent
NewsAttList → Type Subject
Type → EVENT
| NOVELTY
Subject → NATURE
| CULTURE
| SCIENCE
NewsContent → Title Begin-date Grupo1_01 Grupo2_01
Title → TitleAttList TitleContent
TitleAttList → &egr;
TitleContent → textList
Begin-date → Begin-dateAttList Begin-dateContent
Begin-dateAttList → &egr;
Begin-dateContent → textList
Grupo1_01 → Grupo1
| &egr;
Grupo1 → End-date
End-date → End-dateAttList End-dateContent
End-dateAttList → &egr;
End-dateContent → textList
Grupo2_01 → Grupo2
| &egr;
Grupo2 → Body
Body → BodyAttList BodyContent
BodyAttList → &egr;
BodyContent → Grupo3_1n
Grupo3_1n → Grupo3 Grupo3_1n
| Grupo3
Grupo3 → Para
Para → ParaAttList ParaContent
ParaAttList → &egr;
ParaContent → textList
textList → text textList
| &egr;
text → STRPode-se observar que há muitas produções redundantes, mas elas são resultantes de um processo automático de conversão, que pode ser optimizado em futuras versões do sistema: por exemplo, elementos, ElemName, sem atributos não precisam de ter o terminal ElemNameAttList e as respectivas produções nulas.
Além desta gramática abstracta, o editor de DTDs gera ainda as equações para a síntese de um atributo que corresponderá a uma representação intermédia dos documentos que forem introduzidos. Os construtores para este atributo bem como a definição do seu tipo são apresentados mais à frente (Secção 9.2.5.3).
Na próxima secção, descreve-se o editor de estilo.
9.2.3. Editor de Estilo
O editor de estilo, cuja concepção foi o tema principal de uma tese de mestrado [Sou98], tem as seguintes características:
É um dos componentes do sistema S4. A ideia desta integração surge no âmbito do projecto DAVID [HAR99].
Foi gerado pelo SGen a partir de uma especificação SSL da linguagem de especificação de estilo[3], dividida em dois módulos com diferentes proveniências: o primeiro é composto pela gramática abstracta, gramática concreta, atributos e regras de unparsing, e foi desenvolvido pelo implementador; o segundo é constituído por um conjunto de regras que representam o estado inicial da árvore de sintaxe abstracta e é gerado automaticamente pelo editor de DTDs a partir de um atributo, por este sintetizado, que corresponde a uma lista de todos os elementos presentes no DTD em construção e ao qual se quer associar o estilo.
Como resultado, gera as regras de unparsing a juntar à restante especificação SSL gerada pelo editor de DTDs. Depois desta agregação usa-se, de novo, o SGen para gerar um novo editor específico.
O editor de estilos tem uma concepção e um funcionamento muito semelhantes aos do editor de DTDs, por isso, termina aqui a sua descrição. O leitor mais interessado poderá recorrer à leitura da referida tese de mestrado onde é discutida a linguagem implementada e a concepção do editor.
A seguir apresenta-se o funcionamento de um editor específico gerado pelo S4.
9.2.4. Editor Específico
Na figura seguinte, apresenta-se a génese e o esquema de funcionamento de um editor deste tipo.
Figura 9-7. Editor Específico
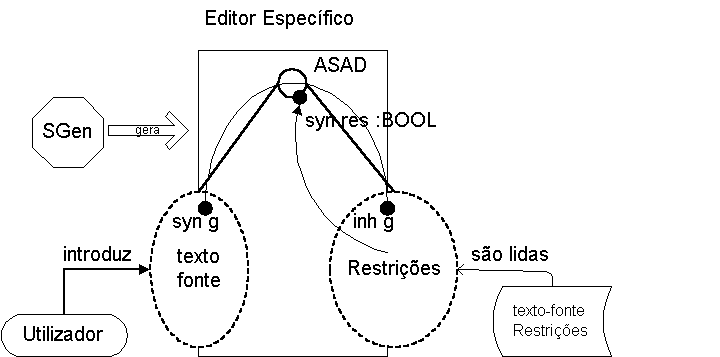
Estes editores têm as seguintes características:
São gerados pelo SGen a partir de uma especificação SSL gerada conjuntamente pelo editor de DTDs e pelo editor de estilo.
Como se pode ver na figura, a sua árvore de sintaxe abstracta decorada é composta por duas subárvores distintas: uma corresponde à árvore da instância documental e é gerada durante a interacção do utilizador com o editor; a outra corresponde às restrições que foram importadas do editor de DTDs, o editor específico contém na sua especificação a gramática da linguagem de restrições e usa-a para reconhecer o texto fonte das restrições e criar esta subárvore.
Como se pode ver, há um atributo g que é sintetizado durante o reconhecimento da instância documental e que depois é herdado pela subárvore das restrições, trata-se da representação intermédia.
Por sua vez, o atributo res é sintetizado na subárvore das restrições. O seu valor é booleano é corresponde à verificação das restrições pela instância documental.
O resto deste capítulo será inteiramente dedicado à linguagem de restrições: sua definição e implementação.
9.2.5. Linguagem de Restrições
A solução adoptada na abordagem com modelos abstractos é semelhante à que se defende mais à frente neste capítulo. Há, no entanto, uma grande diferença. A linguagem utilizada para a especificação de restrições não tinha nenhuma relação com o SGML[4] ou sequer tinha sido pensada para o processamento de documentos estruturados, o que levou a que o documento SGML fosse processado por uma ferramenta (análise sintática) e as restrições por outra (análise semântica). A solução que se apresenta aqui integra estes dois processamentos. Como se poderá ver mais à frente, a sintaxe que se propõe para a especificação das restrições está muito ligada à natureza dos documentos estruturados SGML, tornando mais fácil a sua percepção e aquisição.
Neste momento, vai-se definir a linguagem de restrições.
9.2.5.1. Escolha da linguagem
Em termos abstractos e supondo que as restrições sejam simplesmente locais a um elemento (condições associadas sempre ao elemento), basta enriquecer a definição do elemento da seguinte maneira:
elem : Element( identificador, expressão-conteúdo, restrição);
Um elemento passa a ser um triplo composto por um identificador, uma expressão de conteúdo e uma restrição (simples ou composta). Faltaria agora continuar a definir (em termos abstractos) a estrutura de cada um dos elementos do triplo.
Por outro lado, a sintaxe concreta pretendida para o sistema é a do SGML e já se viu quais as possibilidades de adicionar restrições usando a sintaxe SGML, sem a alterar (Secção 8.3). Qualquer uma das soluções apontadas não prevê uma associação implícita, de uma restrição a um elemento. Essa associação tem de ser feita e a solução mais simples é usar a técnica das bases de dados para relacionar duas tabelas: neste caso, usar um dos campos do triplo.
O campo mais lógico para ser utilizado como chave da relação entre a definição do elemento e da restrição é o identificador do elemento. Porém a realidade é diferente da suposição feita acima e na prática levanta-se outro problema: o mesmo elemento pode aparecer em contextos diferentes e por isso, ter semânticas diferentes. Imagine, por exemplo, o seguinte problema: o primeiro parágrafo de todos os capítulos do livro que se está a escrever deve conter o título do próprio capítulo. Este problema resolve-se colocando uma restrição associada a todos os primeiros parágrafos de cada capítulo, mas só a estes, os restantes parágrafos estarão fora do contexto desta restrição.
Portanto as restrições não devem ser associadas a um elemento mas sim a um contexto. Não se necessita do identificador do elemento mas de algo ligeiramente mais complexo: um selector de contexto.
Assim, utilizando comentários especiais como sintaxe de base para as restrições, obtem-se, numa primeira aproximação, uma sintaxe concreta com a seguinte forma:
<!-- CONSTRAINT sel-contexto (condição) -->
Convencionou-se que:
- Restrição
é o par (sel-contexto condição).
- Condição (de contexto)
é a expressão booleana que se aplica ao conjunto de valores obtidos por aplicação da expressão de selecção.
Ou seja, há duas coisas a considerar numa restrição: a selecção do contexto; e a especificação da restrição propriamente dita, que é uma condição (sobre o contexto).
Este ponto, permitiu abrir a discussão da sintaxe concreta da linguagem de restrições e dividi-la desde já em duas partes: a sub-linguagem de selecção de elementos e a sub-linguagem com a qual se irão especificar as restrições.
A operação de seleccionar os elementos com os quais se quer fazer alguma coisa, ou aos quais se quer aplicar algum processamento, tem sido, desde há algum tempo, uma preocupação das pessoas que trabalham nesta área. Começou por surgir na transformação e na formatação: era preciso seleccionar os elementos que se queriam transformar, ou que se queriam mapear num ou mais objectos com características gráficas (formatação). Este esforço é visível no DSSSL (já discutido na Secção 6.2); o primeiro elemento das suas regras é uma expressão de "query" que selecciona os elementos aos quais será aplicado o processamento especificado. Por último, esta necessidade surgiu ligada às linguagens de "query" para documentos estruturados, como as que foram propostas na última conferência dedicada a esse tópico [RLS98, DeR98, Tom98, Wid8, CCDFPT98].
Depois de uma pesquisa, encontrou-se um conjunto variado de linguagens. Um estudo mais atento permitiu concluir que existe uma característica comum a todas elas: a selecção de contexto.
Assim, chegou-se rapidamente à conclusão de que a operação de selecção necessária para a transformação ou formatação era muito semelhante à necessária nos sistemas de bases de dados documentais para a realização de "queries". Seguindo a mesma linha de raciocínio, pode-se dizer que a linguagem de selectores necessária para as restrições é também equivalente àquelas, tornando possível, desta maneira, tirar partido de uma linguagem já existente com as seguintes vantagens: menos uma sintaxe no mundo das linguagens e consequentemente no sistema que se está a desenvolver, menos dificuldades de implementação, menos trabalho de aprendizagem e de ensino e por tudo isto, menos confusão.
Depois de algum tempo de discussão (moderada pelo W3C - World Wide Web Consortium), começa a emergir algum consenso na utilização do XSLT [XSLT], uma sublinguagem de padrões presente no XSL [XSL] - a proposta de normalização para a especificação de estilos a associar a documentos XML. O XSLT encontra-se já numa fase prévia ao lançamento de uma norma ISO e foi já alvo de um estudo formal por parte de Wadler [Wad99], apresentado na última conferência mundial da área ("Markup Technologies 99") e onde ele define a linguagem usando semântica denotacional (formalismo de cariz funcional utilizado para especificar a sintaxe e a semântica de linguagens - [Paa95]).
Durante esta dissertação, também se procedeu ao estudo de algumas destas linguagens (XSL, XSLT, XQL [RLS98], Element Sets, Lore [Wid8], XQuery [DeR98], XML-GL [CCDFPT98]) e, foi fácil constatar que o XSLT é um denominador comum de uma grande parte delas, aquelas que foram desenvolvidas a pensar em documentos estruturados. Houve, no entanto, uma linguagem que cativou a atenção do autor, pela sua simplicidade e recurso à teoria de conjuntos, a linguagem proposta por Tim Bray [Bray98] na QL'98 - The Query Languages Workshop designada por Element Sets. Um estudo mais atento da linguagem e do seu historial, revelou ser esta a especificação por detrás do conhecido motor de procura Pat comercializado pela OpenText e utilizado na maior parte dos primeiros portais da Internet.
Enquanto as linguagens do tipo XSLT assentam numa sintaxe concreta e específica, a Element Sets define uma notação abstracta baseada em cinco operadores da teoria de conjuntos: contido (within), contém (including), união (+), intersecção (^) e diferença (-). Bray argumenta ser capaz de especificar uma grande percentagem de queries que possam ser necessárias num sistema de arquivo documental à custa da combinação daqueles cinco operadores.
Numa primeira análise e a título comparativo, apresentam-se a seguir dois exemplos, uma query simples e uma mais complicada que irão ser especificadas respectivamente recorrendo a XSLT e a Element Sets.
Exemplo 9-3. Query simples
Pretende-se seleccionar todos os parágrafos (PARA) pertencentes à introdução (INTROD) que contenham uma ou mais notas de rodapé (FOOTNOTE) ou uma ou mais referências (REF) a outros elementos no documento.
Em Element Sets a query seria:
set1 = Set('PARA') within Set('INTROD')
set2 = set1 including Set('FOOTNOTE')
set3 = set1 including Set('REF')
set4 = set2 + set3A função Set selecciona todos os elementos do tipo indicado no argumento. No fim, o resultado da query é dado pelo valor de set4.
Por outro lado, em XSLT, a mesma query seria:
INTROD/PARA[FOOTNOTE $or$ REF]
A query tem duas partes, a primeira de selecção de contexto, INTROD/PARA, que selecciona todos os parágrafos dentro da introdução e a segunda parte de restrição desse contexto, [FOOTNOTE $or$ REF], que restringe o conjunto de elementos seleccionadas àqueles que tenham pelo menos um elemento do tipo FOOTNOTE ou REF.
Depois desta comparação, num caso muito simples, veja-se uma outra situação de interrogação mais elaborada.
Exemplo 9-4. Query mais complexa
Pretende-se agora, seleccionar todos os parágrafos da introdução que contenham uma referência ou uma nota de rodapé mas não ambos.
Em Element Sets a query seria:
set1 = Set('PARA') within Set('INTROD')
set2 = set1 including Set('FOOTNOTE')
set3 = set1 including Set('REF')
set4 = (set2 + set3) - (set2 ^ set3)Apesar de complexa, foi fácil especificar esta query. Bastou excluir (diferença de conjuntos) os elementos resultantes da query anterior que continham ambos os elementos (intersecção de conjuntos), REF e FOOTNOTE.
Veja-se, agora, a especificação em XSLT:
INTROD/PARA[(FOOTNOTE $and$ $not$ REF)
$or$ (REF $and$ $not$ FOOTNOTE)]Do estudo comparativo realizado entre os dois tipos de linguagem e do qual os dois exemplos acima fazem parte, concluiu-se que, em termos da operação de selecção são mais ou menos equivalentes, não se tendo encontrado nenhuma situação que uma solucionasse e a outra não. Vão diferir é no método como fazem a selecção: o XSLT usa a árvore documental e toda a operação de selecção é feita em função dessa estrutura; a Element Sets, por outro lado, não usa a árvore documental, manipula o documento como um conjunto de elementos usando uma sintaxe mais universal. Mas esta diferença existe apenas perante o utilizador que usa a linguagem porque em termos de implementação não se pode fugir às travessias da árvore documental.
Tendo estudado os dois paradigmas era preciso tomar uma decisão: Qual a linguagem a adoptar/adaptar para a sub-linguagem de selecção no S4?
A escolha não recaiu sobre a Element Sets, mas sim sobre uma linguagem do tipo XSLT, a XQL - XML Query Language [RLS98]. Os motivos por detrás desta escolha são muito simples. Apesar dos paradigmas, em termos de selecção, serem equivalentes, as linguagens do tipo XSLT vão além da selecção, permitem ter um segundo nível de selecção baseado em restrições sobre o conteúdo. A ideia é utilizar a sintaxe desse segundo nível de selecção para especificar as condições de contexto em causa; apenas será necessário alterar-lhe a semântica: em lugar de um conjunto de elementos, devolverá um valor "booleano".
Assim, as restrições serão compostas por uma selecção e uma condição, mas integradas na mesma sintaxe. No resto desta secção, descrevem-se ambas as partes da linguagem.
A linguagem XSLT fornece um método bastante simples para descrever a classe de nodos que se quer seleccionar. É declarativa em lugar de procedimental. Apenas é preciso especificar o tipo dos nodos a procurar usando um tipo de padrões simples baseado na notação de directorias de um sistema de ficheiros (a sua estrutura é equivalente à de uma árvore documental). Por exemplo, livro/autor, significa: seleccionar todos os elementos do tipo autor contidos em elementos livro.
A XQL é uma extensão do XSLT. Adiciona operadores para a especificação de filtros, operações lógicas sobre conteúdo, indexação em conjuntos de elementos e restrições sobre o conteúdo dos elementos. Enquanto XSLT está mais orientada para a selecção do contexto, a linguagem XQL é uma notação para a especificação de operações de extracção de informação de documentos estruturados.
No contexto da dissertação, dá-se-lhe uma aplicação diferente. Usa-se uma parte para seleccionar elementos/contexto e outra para calcular condições de contexto sobre esses elementos. A condição de contexto vai ter um comportamento semelhante a um invariante: a linguagem de query selecciona todos os elementos que satisfazem os requisitos da dita query, ou seja, verificam a expressão de selecção; nesta utilização da linguagem, uma acção será executada sempre que um dos elementos seleccionados faça com que se obtenha um valor falso da condição (normalmente a acção corresponde à emissão de uma mensagem de erro).
9.2.5.2. Operadores de restrição
Como já foi dito, começa-se por descrever operadores relacionados com a selecção mas a linha divisória entre selecção e restrição irá sendo diluída ao longo do texto, confundindo-se até, para os casos em que a integração das duas é muito forte.
9.2.5.2.1. Padrões e Contexto
Uma expressão de selecção é sempre avaliada em função de um contexto de procura. Um contexto de procura é um conjunto de nodos a que uma expressão se pode aplicar de modo a calcular o resultado. O contexto de procura é constituído por um nodo pai, todos os nodos filhos e respectivos atributos.
As expressões de selecção são absolutas, o contexto é seleccionado em função do nodo raiz - "/". No caso das condições (subexpressões), o seu contexto é relativo (em função do contexto seleccionado pela expressão de selecção - "."). Na especificação do contexto pode ainda ser usado o operador "//" com o significado de descendência (busca recursiva).
Exemplo 9-5. Selecção de contextos
Seleccionar todos os elementos autor.
//autor
Seleccionar o elemento livro que é a raiz deste documento.
/livro
Seleccionar todos os elementos capítulo cujo atributo tema é igual ao atributo especialidade de livro.
//capítulo[@tema = /livro/@especialidade]
Seleccionar todos os elementos título filhos de um elemento secção.
//secção/título
9.2.5.2.2. Quantificador: todos
O operador "*" quando usado numa expressão de selecção selecciona todos os elementos nesse nível da árvore documental.
Exemplo 9-6. Selecção com "*"
Seleccionar todos os elementos filhos de autor.
//autor/*
Seleccionar todos os elementos nome que sejam netos de livro.
/livro/*/nome
Seleccionar todos os elementos netos do elemento raiz.
/*/*/*
Seleccionar todos os elementos que tenham o atributo identificador instanciado.
//*[@identificador]
9.2.5.2.3. Atributos
Como já se pôde observar nalguns exemplos, o nome de atributos é precedido por "@". Os atributos são tratados como sub-elementos, imparcialmente, sempre que possível. De notar que os atributos não podem ter sub-elementos pelo que não poderão ter operadores de contexto aplicados ao seu conteúdo (tal resultaria numa situação de erro sintáctico). Os atributos também não têm conceito de ordem, são por natureza anárquicos pelo que nenhum operador de indexação deverá ser-lhes aplicado.
Exemplo 9-7. Selecção com atributos
Seleccionar o atributo valor no documento presente.
//@valor
Seleccionar o atributo dólar de todos os elementos preço.
//preço/@dólar
Seleccionar todos os elementos capítulo que tenham o atributo língua instanciado.
//capítulo[@língua]
Seleccionar o atributo língua de todos os elementos capítulo.
//capítulo/@língua
O próximo exemplo não é válido.
preço/@dólar/total
9.2.5.2.4. Condição - sub-query
O resultado de uma query pode ser refinado através de uma sub-query (restrição aplicada ao resultado da query principal), indicada entre "[" e "]" (nos exemplos anteriores já apareceram várias sem nunca se ter explicado a sua sintaxe e semântica).
A sub-query é equivalente à cláusula SQL WHERE. O valor resultante da aplicação de uma sub-query é booleano e só os elementos, do contexto criado pela query, para os quais o valor final seja verdadeiro farão parte do resultado final.
Há operadores nas sub-queries que permitem testar o conteúdo de elementos e atributos. Deixa-se a sua discussão para a secção seguinte pois vão ser utilizados para especificar condições.
Exemplo 9-8. Sub-query
Seleccionar todos os elementos capítulo que contenham pelo menos um elemento excerto.
//capítulo[excerto]
Seleccionar todos os elementos título pertencentes a elementos capítulo que tenham pelo menos um elemento excerto.
//capítulo[excerto]/titulo
Seleccionar todos os elementos autor pertencentes a elementos artigo que tenham pelo menos um elemento excerto e onde autor tenha email.
//artigo[excerto]/autor[email]
Seleccionar todos os elementos artigo que contenham elementos autor com email.
//artigo[autor/email]
Seleccionar todos os elementos artigo que tenham um autor e um título.
//artigo[autor][titulo]
Como se pode observar nalguns destes exemplos, algumas das restrições que se pretende formular sobre os documentos podem ser especificadas com os construtores e operadores já apresentados. A linha divisória entre a selecção e a restrição parece já um pouco diluída. Como os restantes operadores que se podem usar nas sub-queries já permitem interrogar conteúdos vão ser discutidos como uma aproximação à especificação de condições de contexto.
9.2.5.2.5. Expressões booleanas
As expressões booleanas podem ser usadas nas sub-queries permitindo especificar condições contextuais como a restrição de valores a um domínio. Uma expressão booleana tem a seguinte forma:
val-esquerda $operador$ val-direita
Os operadores têm a forma $operador$ e são normalmente binários: tomam como argumentos um valor à esquerda e um valor à direita.Um operando pode tomar três tipos de valor: pode representar o conteúdo de um elemento (é utilizado o nome do elemento), pode ser o valor de um atributo (usa-se o nome do atributo como referência) ou ainda, uma constante numérica ou carácter.
Com estes operadores e o agrupamento por parentesis podem especificar-se queries bastante complexas.
Exemplo 9-9. Operadores booleanos
Seleccionar todos os elementos autor que tenham um email e um url.
autor[email $and$ url]
No universo das queries, o resultado seria o conjunto de autores que tivessem email e url. De acordo com a nova semântica que se quer associar a esta linguagem, a expressão é uma especificação de uma restrição aplicada a todos os elementos autor e o respectivo resultado, uma mensagem de erro para todos os autores que não tivessem um email ou um url.
Seleccionar todos os elementos autor que tenham um email ou um url e pelo menos uma publicação.
autor[(email $or$ url) $and$ publicação]
Seleccionar todos os elementos autor que tenham um email e nenhuma publicação.
autor[email $and$ $not$ publicação]
Seleccionar todos os elementos autor que tenham pelo menos uma publicação e não tenham email nem url.
autor[publicação $and$ $not$ (email $or$ url)]
Como se pode ver, todas estas queries podem ser encaradas como restrições, apenas é preciso dar uma interpretação diferente aos resultados. A partir deste ponto e uma vez que os operadores seguintes são dirigidos ao conteúdo, substituem-se as referências a queries por referências a restrições.
9.2.5.2.6. Equivalência
A igualdade é notada por = e a desigualdade por !=. Alternativamente podem ser usados $eq$ e $neq$.
Podem ser usadas strings nas expressões desde que limitadas por aspas simples ou duplas.
Na comparação com o conteúdo de elementos o operador value() está implícito. Por exemplo nome='Carlos' é uma abreviatura de nome!value()='Carlos'. O operador referido quando aplicado a um nodo do grove dá como resultado o conteúdo textual desse nodo.
Como foi dito no fim da última secção, vai-se agora dar exemplos de restrições. Apesar de algumas parecerem um pouco "artificiais", elas são necessárias para exemplificar outros operadores.
Exemplo 9-10. Equivalência
Garantir que todos os autores têm o sub-elemento organização preenchido com o valor 'U.Minho'.
autor[organização = 'U.Minho']
Garantir que todos os elementos têm o atributo língua preenchido com o valor 'pt'.
*[@língua = 'pt']
Imagine-se um universo documental com vários documentos relativos aos curriculae de vários autores e que estes documentos foram gerados automaticamente a partir de uma base de dados. Agora pretende-se garantir que todas as publicações têm o sub-elemento nome do elemento autor preenchido com um valor igual ao sub-elemento nome que figura no elemento curriculum.
publicação/autor[nome = /curriculum/nome]
Esta é uma restrição complexa uma vez que envolve a comparação de elementos localizados em diferentes ramos da árvore documental, daí a necessidade de recorrer a duas expressões de selecção.
Passa-se agora para uma situação corrente numa instituição. O prazo para a entrega da proposta em que a equipa tem vindo a trabalhar foi ultrapassado. Em conversa com a entidade competente a equipe é informada de que os documentos ainda vão a tempo se forem entregues nos próximos dois dias mas as datas constantes nos documentos têm de ser inferiores a '1999-12-22'.
Pode-se adaptar o editor para fazer essa verificação acrescentando-lhe a seguinte condição de contexto:
data[. < '1999-12-22']
O operador . selecciona o conteúdo do contexto actual. Assumiu-se que as datas estavam normalizadas, de qualquer modo, as que não estiverem não passarão pela restrição e serão detectadas.
A linguagem possui todos os operadores relacionais habituais, cuja utilização não foi aqui exemplificada. Porém, a sua semântica é bem conhecida e o seu lugar na linguagem será bem especificado na próxima secção onde se define rigorosamente a linguagem de restrições.
9.2.5.3. Definição da linguagem de restrições -- CL
As restrições são especificadas junto com o DTD usando secções de comentário especiais (preservadas pelo parser SGML, podendo por isso ter uma sintaxe mais alargada). A restrição propriamente dita é especificada em CL ("Constraint Language"), cuja sintaxe é um subconjunto da sintaxe da XQL apresentada na secção anterior. A declaração de uma restrição tem a seguinte forma final:
<!- - CONSTRAINT expressão-CL acção - - >
Onde:
- CONSTRAINT
É uma palavra reservada que serve para indicar ao interpretador das restrições que este não é um comentário SGML mas uma expressão em CL que deverá ser processada.
- expressão-CL
É a restrição semântica, escrita na linguagem CL (especificada à frente) e que contém a expressão de selecção e a condição a ser verificada.
- acção
É a acção que deverá ser executada sempre que o cálculo da expressão resultar num valor falso. Nesta primeira versão, corresponderá apenas a uma string que conterá uma mensagem de erro a ser mostrada sempre que a acção for despoletada.
Tendo definido o enquadramento das restrições com o SGML, vai-se agora apresentar a definição atributiva da CL.
Apesar da sintaxe da CL estar contida na sintaxe da XQL, não é um subconjunto desta; semanticamente são completamente diferentes, como se poderá ver à frente.
Antes de introduzir a especificação da linguagem é bom fazer uma revisão da arquitectura do sistema S4 e ver de que modo este componente irá interagir com os outros. Como já foi referido, o componente central do sistema é o editor de DTDs ao qual se pretende acrescentar a facilidade de especificar restrições; é pois este editor que tem de reconhecer e processar CL. Portanto, as expressões para selecção dos nodos e cálculo das condições (correspondentes às restrições da CL) têm de ser geradas por este editor e incluídas na gramática de atributos produzida pelo editor de DTDs e que define o editor específico. Levanta-se aqui um problema: onde colocar o código correspondente às restrições? As restrições dependem do contexto e este depende da instância documental que é introduzida pelo utilizador. Há duas soluções para o problema:
Sintetizar strings de expressões para as condições e fazer corresponder as condições de contexto ao cálculo das respectivas expressões. Esta solução pode ser implementada dentro da filosofia das gramáticas de atributos, definindo uma gramática de ordem superior onde estão especificadas regras de cálculo para os atributos que são expressões a ser calculadas.
Criar uma máquina abstracta para a interpretação das condições. Esta máquina abstracta trabalha sobre uma representação intermédia do documento que será sintetizada num atributo, durante a edição. As restrições serão traduzidas para instruções dessa máquina abstracta correspondendo a regras de cálculo sobre esta representação intermédia.
Das duas soluções acima enunciadas optou-se pela segunda porque o sistema gerador em uso não suporta gramáticas de atributos de ordem superior e, além disso, com a máquina abstracta obtem-se uma solução simples e que integra bem com os restantes componentes que se estão a gerar.
Assim, a máquina abstracta em causa é constituída por um interpretador que recorre a um conjunto pré-definido de funções que realizam a semântica das restrições e trabalham sobre uma representação intermédia do documento, designada por grove (Secção 6.2.4.1), que é uma estrutura arbórea universalmente aceite para representar documentos anotados (conteúdo, anotação, atributos, ...). Estas funções que actuam sobre o grove são o que se denomina por vezes de "tree-walkers".
No S4, o grove corresponde a um atributo do axioma da gramática correspondente do DTD que é sintetizado durante a edição do documento. As regras de cálculo para a construção deste atributo são geradas, juntamente com a gramática de atributos, pelo editor de DTDs. Portanto, o editor específico final sintetiza este atributo à medida que o utilizador for introduzindo o documento.
A seguir, apresenta-se a definição do tipo de dados para este atributo, usando a sintaxe SSL:
Um grove é vazio ou é um nodo -- isto garante que há um elemento raiz e que em termos estruturais o documento corresponde a uma árvore.
Grove : Cgvazio () | Cgrove (Nodo)Há três tipos de nodos: os que contêm informação estrutural, representativos de um elemento, o seu identificador é o nome do elemento; os que contêm texto, identificados pelo seu construtor (não têm um identificador único, perante um nodo destes só se sabe que que o seu conteúdo é texto); e os nodos que guardam informação sobre os atributos e que são identificados pelo nome do atributo.
Nodo : Cnodo (ident ListaAtrib Conteúdo) | Cnodotexto (texto) | Cnodoatrib (ident valor)A lista de atributos é composta por zero ou mais nodos.
ListaAtrib : Clavazia () | Clatrib (Nodo ListaAtrib)O conteúdo de um nodo é uma lista de nodos.
Conteúdo : Ccont (ListaNodo)
Uma lista de nodos é composta por zero ou mais nodos.
ListaNodo : Clnvazia () | Clnodo (Nodo ListaNodo)Pode parecer que ListaAtrib e ListaNodo representam a mesma estrutura o que não corresponderá bem à realidade, enquanto que os nodos pertencentes a ListaAtrib serão construídos por Cnodoatrib e, portanto, singulares, cada nodo de ListaNodo poderá ser de qualquer um dos três tipos acima representando muitas vezes uma sub-árvore do grove.
Note-se que esta definição é equivalente à definição apresentada na Secção 6.2.4.1 quando se analisava o processo de construção de um grove. Note também que, além do tipo de dados Grove, cada regra define um outro tipo de dados que será usado à frente na especificação semântica da linguagem de restrições, nomeadamente: Nodo, Conteúdo, ListaNodo e ListaAtrib.
Veja-se agora um exemplo de construção de um atributo do tipo Grove.
Exemplo 9-11. Construção de um atributo do tipo Grove
Considere o seguinte excerto já apresentado no Capítulo 4:
</EXCERTO> <PARAG>O <toponimico valor='PRÚSSIA, Rei da'> rei da Prussia</toponimico> andava no exercito. ... Recolheo-se a <toponimico valor='VERDUN, Praça de'> Praça de Verdun</toponimico> e ahi ficou sitiado pelos franceses. Mas quem não poderia aqui fazer reflexoens? A <toponimico valor="PRÚSSIA">Prussia</toponimico> queria isto, elle não fazia o negocio deveras. </PARAG></EXCERTO>
O atributo g, do tipo Grove associado a EXCERTO (suposto axioma), será construído pela seguinte expressão, sintetizada durante a edição/reconhecimento do documento acima:
Cgrove(
Cnodo(
"EXCERTO"
Clavazia()
Ccont(
Clnodo(
Cnodo(
"PARAG"
Clavazia()
Ccont(
Clnodo(
Cnodotexto(
"O " )
Clnodo(
Cnodo(
"toponimico"
Cla(
Cnodoatrib(
"VALOR"
"PRÚSSIA, Rei da")
Clavazia()
)
Ccont(
Clnodo(
Cnodotexto(
"rei da Prussia")
Clnvazia()
)
)
Clnodo(
Cnodotexto(
" andava no exercito.
...
Recolheo-se a")
Clnodo(
Cnodo(
"toponimico"
Cla(
Cnodoatrib(
"VALOR"
"VERDUN, Praça de")
Clavazia()
)
Ccont(
Clnodo(
Cnodotexto(
"Praça de Verdun")
Clnvazia()
)
)
)
Clnodo(
Cnodotexto(
" e ahi ...reflexoens?")
Clnvazia()
) ) ) ) ) ) ) ) ) ) )Cada restrição em CL, dará origem a regras de cálculo da referida máquina virtual que trabalha sobre o grove. Este corresponde a um atributo que foi sintetizado pelo parser do documento e que é herdado por todos os símbolos não-terminais da gramática que especifica a linguagem de restrições.
Usam-se gramáticas de atributos para especificar a sua sintaxe e semântica. Para que a definição aqui apresentada não fique muito pesada será usada a sintaxe SSL apenas para a declaração dos atributos e especificação das suas equações de cálculo.
Para uma melhor identificação as produções encontram-se numeradas de 1 a n, sendo 1 a produção correspondente ao axioma.
A estrutura seguida para a especificação de cada produção da linguagem CL é a seguinte:
n <produção> <declaração atributos> <equações de cálculo>Por sua vez <declaracao atributos> é:
<Símbolo> {(modo tipo nome-atributo;)+};Para efeitos de legibilidade, os atributos são declarados na produção correspondente à sua primeira utilização.
Por fim, a gramática de atributos que define a linguagem CL é:
CLexp → Contexto Cond CLexp { inh Grove g; syn BOOL resultado; }; Contexto { inh ListaNodo ic; syn ListaNodo fc; }; /* contexto calculado */ Cond { inh ListaNodo contexto; syn BOOL fb; }; /* resultado boolean final */ { CLexp.resultado = Cond.fb; Contexto.ic = Clnodo(CLexp.g,Clnvazia()); Cond.contexto = Contexto.fc; };Uma expressão em CL é estruturalmente constituída por duas partes: um selector de contexto e uma condição. O símbolo não-terminal (NT) CLexp irá ter dois atributos, um herdado que corresponde ao grove e um sintetizado que ficará com o resultado da avaliação da condição no contexto especificado: g, resultado.
O cálculo da expressão de contexto deverá resultar num conjunto de nodos do grove (muitas vezes singular) e é sintetizado num atributo do NT Contexto: fc. O contexto inicial é passado através dum atributo herdado, ic, e é composto por uma lista de nodos singular, apenas com um nodo, o grove.
O contexto final é depois passado ao NT Cond que herda um atributo contexto que contêm a lista de nodos onde tem de ser verificada a condição. Por último, Cond tem também um atributo sintetizado que corresponde à conjunção lógica dos resultado da avaliação da condição para cada nodo na lista de nodos contexto.
Contexto → '/' RelContexto RelContexto { syn BOOL fc; inh ListaNodo ic; }; { Contexto.fc = RelContexto.fc; RelContexto.ic = Contexto.ic; };A expressão de contexto '/' representa o nodo raiz do grove. Como é o contexto inicial não é alterado (apenas copiado para baixo na árvore de derivação).
Contexto → RelContexto { Contexto.fc = RelContexto.fc; RelContexto.ic = Contexto.ic; };Como a expressão '/' é opcional assume-se o contexto inicial.
RelContexto → elem-id '/' RelContexto elem-id { syn IDENT v; }; { RelContexto.fc = RelContexto$2.fc; RelContexto$2.ic = Sel(elem-id.v, RelContexto.ic); };elem-id é um símbolo terminal que tem um atributo intrínseco (proveniente da análise léxica) cujo valor corresponde ao nome de um elemento.
A função Sel tem a seguinte assinatura:
Sel : ident ListaNodo → ListaNodo
Ou seja, funciona como um filtro. Restringe o conjunto de nodos passado como segundo parâmetro, aos nodos que tenham o nome igual ao primeiro parâmetro.
RelContexto → elem-id '/' '/' RelContexto { RelContexto.fc = RelContexto$2.fc; RelContexto$2.ic = Descendentes(Sel(elem-id.v, RelContexto.ic); };A função Descendentes tem a seguinte assinatura:
Descendentes : ListaNodo → ListaNodo
Recebe uma lista de nodos como entrada e dá como resultado uma lista com todos os nodos dos sub-groves com raiz correspondente aos nodos na lista original.
RelContexto → '*' { RelContexto.fc = Filhos(RelContexto.ic); };A função Filhos tem a seguinte assinatura:
Filhos : ListaNodo → ListaNodo
Recebe uma lista de nodos e devolve uma lista de nodos correspondentes aos filhos dos nodos pertencentes à lista inicial.
RelContexto → elem-id { RelContexto.fc = Sel(elem-id.v, RelContexto.ic); };RelContexto → '@' Atrib Atrib { syn IDENT v; }; { RelContexto.fc = SelAtrib(Atrib.v, RelContexto.ic); };A função SelAtrib tem a seguinte assinatura:
SelAtrib : ident ListaNodo → ListaAtrib
Esta função dá como resultado uma lista de nodos do tipo atributo. Estes resultam de selecionar os nodos das listas de atributos dos nodos pertencentes ao contexto actual, RelContexto.ic, com identificador igual a Atrib.v.
Note-se que, atendendo à definição, não há diferença entre os tipos ListaNodo e ListaAtrib. Existe apenas uma diferença semântica na sua manipulação daí que, por vezes, a sua utilização está apenas relacionada com a legibilidade da especificação.
Atrib → atrib-id atrib-id { syn IDENT v; }; { Atrib.v = atrib-id.v; };atrib-id.v é um atributo intrínseco proveniente da análise léxica.
Atrib → '*' { Atrib.v = "ALL"; };ALL é um identificador especial, selecciona todos os atributos. Com este selector pode-se colocar restrições sobre todos os atributos ou sobre todos os elementos que tenham atributos instanciados.
Cond → '[' Exp ']' Exp { inh ListaNodo contexto; }; { Cond.fb = Exp.fb; Exp.contexto = Cond.contexto};Primeira produção respeitante à derivação de condição.
Como já foi dito, será sintetizado um valor booleano.
Exp → Termo OR Exp Termo { inh ListaNodo contexto; syn BOOL fb; }; { Exp.fb = Termo.fb || Exp.fb; Termo.contexto = Exp.contexto; Exp$2.contexto = Exp.contexto; };Exp → Termo { Exp.fb = Termo.fb; Termo.contexto = Exp.contexto; };Termo → Factor AND Termo Factor { inh ListaNodo contexto; syn BOOL fb; }; { Termo.fb = Factor.fb && Termo.fb; Factor.contexto = Termo.contexto; Termo$2.contexto = Termo.contexto; };Termo → Factor { Termo.fb = Factor.fb; Factor.contexto = Termo.contexto; };Factor → SubExp SubExp { inh ListaNodo contexto; syn BOOL fb; }; { Factor.fb = SubExp.fb; SubExp.contexto = Factor.contexto; };Factor → NOT SubExp { Factor.fb = !SubExp.fb; SubExp.contexto = Factor.contexto; };Factor → '(' Exp ')' { Factor.fb = Exp.fb; Exp.contexto = Factor.contexto; };SubExp → Operando EQ Operando Operando { inh ListaNodo contexto; syn ListaSTR valor; }; { SubExp.fb = ComparaValores(Operando$1.valor, Operando$2.valor, EQ); Operando$1.contexto = SubExp.contexto; Operando$2.contexto = SubExp.contexto; };A função ComparaValores tem a seguinte assinatura:
ComparaValores : ListaSTR ListaSTR STR → BOOL
A função ComparaValores recebe três argumentos, duas listas de valores e uma constante, e tem o seguinte funcionamento: começando no início de cada lista (as listas têm o mesmo comprimento), a função compara o elemento na posição i da primeira lista com o elemento na mesma posição na segunda lista, passa depois ao elemento seguinte fazendo o mesmo e assim sucessivamente até ter percorrido as duas listas; como resultado é feita a conjunção lógica de todos os valores booleanos resultantes das comparações; se uma das listas for singular, será tratada como constante e esse elemento será comparado com todos os elementos da outra lista. O terceiro argumento indica qual o tipo de comparação que a função deverá efectuar.
SubExp → Operando NEQ Operando { SubExp.fb = ComparaValores(Operando$1.valor, Operando$2.valor, NEQ); Operando$1.contexto = SubExp.contexto; Operando$2.contexto = SubExp.contexto; };SubExp → Operando LT Operando { SubExp.fb = ComparaValores(Operando$1.valor, Operando$2.valor, LT); Operando$1.contexto = SubExp.contexto; Operando$2.contexto = SubExp.contexto; };SubExp → Operando GT Operando { SubExp.fb = ComparaValores(Operando$1.valor, Operando$2.valor, GT); Operando$1.contexto = SubExp.contexto; Operando$2.contexto = SubExp.contexto; };SubExp → Operando LEQ Operando { SubExp.fb = ComparaValores(Operando$1.valor, Operando$2.valor, LEQ); Operando$1.contexto = SubExp.contexto; Operando$2.contexto = SubExp.contexto; };SubExp → Operando GEQ Operando { SubExp.fb = ComparaValores(Operando$1.valor, Operando$2.valor, GEQ); Operando$1.contexto = SubExp.contexto; Operando$2.contexto = SubExp.contexto; };Operando → elem-id { Operando.valor = Conteúdo(Sel(elem-id.v, Operando.contexto)); };A função Conteúdo tem a seguinte assinatura:
Conteúdo : ListaNodo → ListaSTR
Um dos componentes dos nodos tipo elemento é o seu conteúdo (relembrar a estrutura de um grove). Esta função extrai esse conteúdo dos nodos pertencentes ao contexto que lhe é passado e devolve-os numa lista.
Operando → '.' { Operando.valor = Conteúdo(Operando.contexto); };Operando → '@' atrib-id { Operando.valor = Valor (SelAtrib(atrib-id.v, Operando.contexto)); };A função Valor é semelhante à função Conteúdo, só que aplicada a atributos. Valor devolve uma lista correspondente aos valores dos atributos cujos identificadores lhe são passados como parâmetro.
Tem a seguinte assinatura:
Valor : ListaAtrib → ListaSTR
Operando → Expnum Expnum {syn INT vnum; }; { Operando.valor = INTtoSTR(Expnum.vnum); };Operando → string { Operando.valor = string.v; };string.v é um atributo intrínseco proveniente da análise léxica.
Operando → '(' SubExp ')' { Operando.valor = SubExp.fb; };Operando → Selec Selec { syn ListaNodo fc; }; { Operando.valor = Conteúdo(Selec.fc); };O NT Selec representa o path para um elemento ou atributo noutro ponto da árvore que não o nodo corrente ou algum da sua descendência. Será usado para derivar condições que comparam valores localizados em sub-groves distintos.
Selec → '/' RelSelec RelSelec { syn ListaNodo fc; inh ListaNodo ic; }; {Selec.fc = RelSelec.fc; RelSelec.ic = Selec.ic; };A construção da expressão de contexto para Selec será muito semelhante à que foi usada para o NT Contexto.
Selec → RelSelec {Selec.fc = RelSelec.fc; RelSelec.ic = Selec.ic; };RelSelec → elem-id '/' RelSelec {RelSelec.fc = RelContexto$2.fc; RelContexto$2.ic = Sel(elem-id.v, RelSelec.ic); };RelSelec → elem-id { RelSelec.fc = Sel(elem-id.v, RelSelec.ic); };RelSelec → '@' atrib-id { RelSelec.fc = SelAtrib(Atrib.v, RelSelec.ic); };Expnum → TermoN OpAd ExpNum TermoN { syn INT vnum; }; { Expnum.vnum = (OpAd.op == '+') ? TermoN.vnum + Expnum$2.vnum : TermoN.vnum + Expnum$2.vnum; };As expressões aritméticas são semelhantes às expressões lógicas. O esquema de prioridades reflectido na gramática é o mesmo, apenas muda a simbologia dos operadores.
Expnum → TermoN { Expnum.vnum = TermoN.vnum; };TermoN → FactorN OpMul TermoN FactorN { syn INT vnum; }; { TermoN.vnum = (OpMul.op == '*') ? FactorN.vnum * TermoN$2.vnum : FactorN.vnum / TermoN$2.vnum; };TermoN → FactorN { TermoN.vnum = FactorN.vnum; };FactorN → num {FactorN.vnum = num.v; };FactorN → '(' Expnum ')' {FactorN.vnum = Expnum.vnum; };
Termina aqui a especificação da linguagem de restrições.
Na secção seguinte, ilustra-se a utilização da linguagem, aplicando-a a exemplos que têm vindo a ser introduzidos.
9.2.5.4. Aplicação aos casos de estudo apresentados
Ao longo dos capítulos anteriores, foram apresentados vários problemas onde era necessário especificar condições de contexto que teriam de ser verificadas de modo a limitar os erros no conteúdo dos respectivos documentos. Vai-se, agora, ver como especificar cada uma daquelas restrições com a linguagem que se acabou de definir.
Identifica-se cada exemplo e indica-se a solução proposta na altura em que foi apresentado:
- Reis e Decretos
Este foi o exemplo utilizado no capítulo anterior para ilustrar a abordagem à especificação de restrições com modelos abstractos. Na altura, especificaram-se as restrições em CAMILA da seguinte forma:
rei(r) = { if(nome_(r) notin PessFamDB -> nome_(r) ++ "Não existe..."), if(datan_(r) > datam_(r) -> nome_(r) ++ "Morreu antes de nascer."), if(datam_(r) - datan(r) > 120 -> nome_(r) ++ "Viveu demais!"), if(!all( x<-decreto_l(r) : datan_(r) < data_(x) /\ data_(x) < datam_(r)) -> nome_(r) ++ "fez um decreto fora da sua vida!") };Usando CL, as mesmas restrições seriam assim especificadas:
<!-- CONSTRAINT /rei[datan/@valor < datam/@valor] "Morreu antes de nascer" --> <!-- CONSTRAINT /rei[datam/@valor-datan/@valor < 120] "Viveu muito tempo" --> <!-- CONSTRAINT /rei/decreto[(data/@valor < /rei/datam/@valor) $and$ (data/@valor > /rei/datan/@valor)] "Fez decretos fora da sua vida" -->Na comparação das datas usou-se o atributo valor pois é aqui que está o valor normalizado da data (lembrar discussão sobre a normalização de conteúdos: Exemplo 7-2).
Para exprimir a primeira condição seria necessária uma ligação a uma base de dados externa. Esta facilidade não está ainda contemplada na CL.
- Arqueologia
No Capítulo 7, usou-se um caso real, a edição dos "Arqueosítios do Noroeste português", para exemplificar a necessidade de invariantes durante a edição de documentos. Especificamente, há dois campos, latitude e longitude, cujo conteúdo deve estar compreendido dentro de determinado domínio. Está prevista uma ligação a um sistema de informação geográfico e aquele domínio é definido pelas coordenadas das extremidades do mapa.
Em CL, esta restrição seria especificada da seguinte forma:
<!-- CONSTRAINT //latitude[(.>39) $and$ (.<42)] "Latitude errada!" - -> <!- - CONSTRAINT //longitude[(.>0) $and$ (.<55)] "Longitude errada!" -->Ou ainda, e relembrando que um contexto de procura é constituído por todos os nodos que são filhos do nodo pai indicado e respectivos atributos, mais os atributos do nodo pai:
<!-- CONSTRAINT /arqueositio[(latitude>39) $and$ (latitude<42)] "Latitude errada!" --> <!-- CONSTRAINT /arqueositio[(longitude>0) $and$ (longitude<55)] "Longitude errada!" -->Esta última solução só testa a condição para os elementos latitude e longitude do arqueosítio. Se existirem outros elementos latitude e longitude noutro contexto a condição de contexto não lhes será aplicada.
- O sistema noticioso automático
Relembre-se o exemplo introduzido atrás, neste capítulo (Exemplo 9-2). Existe um sistema noticioso automático que funciona para mensagens que obedeçam a uma certa estrutura e cujo conteúdo respeite certas restrições semânticas. O problema da validação estrutural já foi tratado tendo ficado por resolver o problema das restrições. Neste momento, já se pode especificar as restrições usando a nova linguagem proposta na secção anterior.
A primeira restrição semântica exige que todas as notícias do tipo Event tenham uma data de fim (End-date). Em CL a sua definição é:
<!--CONSTRAINT: /News[End-date != Null] "End-date vazia!!!" -->A segunda restrição é um predicado que diz que se a Notícia é do tipo Event então a data de fim terá que ser superior à data de início. Em CL é definida assim:
<!--CONSTRAINT: /News[Begin-date <= End-date] "Datas inconguentes!" -->Neste exemplo, não se abordou o problema da normalização de datas. No entanto, adoptando a solução apresentada num capítulo anterior (Secção 7.1.2) para a normalização de conteúdos, as restrições seriam especificadas de modo muito semelhante: os operandos das comparações seriam atributos e não elementos.
9.2.6. Estado actual do S4
Neste momento, o estado de implementação do S4 é o seguinte:
O editor de DTDs está implementado sem restrições. No entanto, no decorrer desta dissertação as regras de conversão de DTDs para GAs foram revistas várias vezes daí resultando a versão em apêndice (Apêndice C), que é muito diferente da que se encontra implementada [Lop98] o que levará a uma reimplementação num futuro próximo.
A linguagem de restrições tem agora a sua sintaxe e semântica especificadas numa gramática de atributos. A sua implementação com o SGen é imediata (tema de outra tese de mestrado em curso).
O editor de estilos está implementado [Sou98], mas a ligação ao editor de DTDs necessita de ser refinada; a linguagem para a especificação de estilos deverá também ser revista o que reconduzirá a nova implementação.
Neste capítulo, apresentou-se o contributo mais importante da dissertação: a definição formal da linguagem de restrições e a construção de uma arquitectura funcional que integra o processamento desta nova linguagem com o S4, um sistema que se está a desenvolver com o objectivo de suportar o ciclo de vida dos documentos SGML.
A dissertação termina no próximo capítulo com uma síntese do trabalho realizado e deixando alguns indicadores de trabalho futuro.