6.2. Semântica Dinâmica: o DSSSL
Normalmente, no universo do processamento de linguagens de programação dá-se o nome de "Semântica Dinâmica" à geração de código, devido ao facto de dessa geração resultar o significado operacional (a obter em tempo de execução) do programa. Como nesta secção se aborda a geração do documento final, partindo do documento estruturado original, por analogia com o processo de compilação, nada mais natural do que atribuir-lhe o mesmo nome.
Como o interesse dos utilizadores pelo SGML era crescente, a indústria de software começou a reagir. Estava-se no início dos anos noventa e os editores estruturados baseados em SGML começaram a aparecer no mercado oriundos de esforços empresariais ou académicos.
Como já foi referido várias vezes ao longo deste documento, o SGML especifica apenas estrutura, não fornece qualquer facilidade para a especificação de aparência visual ou formato. Isto criou uma lacuna que começou a ser colmatada da mais óbvia mas pior maneira possível. Cada editor de SGML tinha a sua linguagem própria para associar estilo aos documentos SGML. A portabilidade do SGML estava assim ameaçada, pois os documentos eram apenas parcialmente compatíveis: o mesmo documento SGML podia ser transportado de um editor para outro sem perdas nem necessidade de alterações estruturais ou de conteúdo, mas todo o estilo especificado dentro de um editor era automaticamente perdido quando o documento se manuseava num outro editor diferente.
Foi, pois, na tentativa de normalizar o que faltava do processo que um comité ISO lançou a norma ISO/IEC 1079:1996 [Cla96], hoje conhecido como "Document Style Semantics and Specification Language" (DSSSL) . O DSSSL foi formalmente definido em SGML mas é um pouco diferente das linguagens de anotação que normalmente se definem em SGML; isto deve-se ao facto de a operação de transformação/formatação necessitar de algum processamento. Assim foi preciso dotar a norma de uma linguagem de cálculo. Adoptou-se um subconjunto da norma das linguagens funcionais, o Scheme; este subconjunto forma uma linguagem declarativa e em termos de processamento é livre de efeitos laterais.
Com este novo elemento, já é possível montar uma cadeia de processamento documental completamente normalizada. Essa cadeia compreende a criação/utilização de três ficheiros e várias acções/processos sobre eles:
primeiro há que definir a estrutura do documento que se quer criar -- utiliza-se o SGML na definição de um DTD, que normalmente é guardado num ficheiro com a estensão ".dtd".
com um editor, específico de SGML ou não, cria-se a instância do documento, que será depois validada por um parser embutido no editor ou externo a este; normalmente as instâncias dos documentos guardam-se em ficheiros com a estensão ".sgm".
uma vez criado o DTD pode e deve-se criar a especificação de estilo em DSSSL para esse DTD, que é guardada num ficheiro com a estensão ".dsl"; para que o sistema produza o resultado desejado, passam-se estes três ficheiros a um motor de formatação que percebe de SGML e DSSSL e que produz o resultado desejado: RTF, TeX, HTML, ou outro.
Fazer um motor de formatação capaz de entender SGML e DSSSL é uma tarefa difícil e penosa. Decorridos já quatro anos desde a publicação do DSSSL apenas três tentativas são dignas de registo: o SENG da empresa "Copernican Solutions", o Hybrick dos laboratórios "Fujitsu" e o Jade de James Clark [Cla96b]. O último foi o primeiro a surgir, fruto do trabalho do editor do DSSSL. Hoje, continua a ser o mais utilizado quer na indústria quer no meio académico, facto a que não é alheia a particularidade de se tratar de um produto livre de direitos comerciais.
6.2.1. Componentes funcionais de especificação
O DSSSL esteve vários anos em desenvolvimento e sofreu várias alterações nesse período. A complexidade que lhe é inerente é bastante alta o que justifica a pouca bibliografia existente apesar dos esforços realizados nesse sentido; além do texto da norma [Cla96], algumas tutoriais bastante superficiais [Ken97, DuC97, Spe98] e duas mais recentes e mais completas [Ger96, Pre97], há apenas aquilo que se baptizou de "DSSSL Documentation Project" que é um esforço global, levado a cabo através da Internet com a colaboração de todos os utilizadores de DSSSL, para a criação de um livro didáctico [Mul98], que sirva quer a principiantes quer a utilizadores experientes.
O modelo conceptual subjacente à linguagem é bastante complexo (Figura 6-1), pelo que se vai analisar a sua estrutura e depois cada uma das suas subcomponentes separadamente.
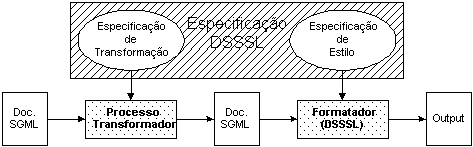
O DSSSL é essencialmente uma linguagem de especificação na qual se podem distinguir quatro sublinguagens. Duas principais, para preparar o documento final e formatá-lo:
uma linguagem para especificar a transformação de um ou mais documentos SGML num ou mais documentos SGML.
uma linguagem para especificar a aplicação de atributos de formatação a um documento SGML.
E outras duas auxiliares:
uma linguagem de interrogação, Standard Document Query Language (SDQL), que se pode utilizar para identificar e seleccionar partes de um documento SGML.
uma linguagem funcional de cálculo de expressões, que é um subconjunto do padrão para as linguagens funcionais - Scheme, que serve de suporte e de ligação às outras linguagens.
Em termos de implementação e referindo-nos ao jade, a única sublinguagem totalmente implementada é a de especificação da formatação. Todas as outras foram parcialmente implementadas e continuam a sê-lo à medida das necessidades. Necessidades estas que têm a ver com a formatação dos documentos, que como é a primeira necessidade dos utilizadores é a que tem de ser servida primeiro para que a tecnologia seja adoptada e tenha sucesso.
6.2.2. Modelo Conceptual
Uma especificação DSSSL compreende duas partes:
uma especificação de transformação - há situações em que o conteúdo do documento final pretendido difere do original, é um subconjunto ou corresponde a uma reordenação do conteúdo inicial; nestas situações o documento original tem que passar por uma fase de transformação antes de ser formatado.
uma especificação de estilo - que vai dirigir a formatação.
O transformador actua sobre o documento SGML de origem e transforma-o, de acordo com a especificação, dando origem a um novo documento SGML. Este novo documento é por sua vez passado a um formatador que o vai formatar de acordo com a especificação de estilo dando origem a um documento no formato previamente seleccionado para o resultado final (RTF, Postscript, PDF, HTML, etc).
A especificação de estilo controla parcialmente o processo de formatação (definição de margens, escolha do tipo de letra, tamanho da letra). O controlo é apenas parcial porque há muitos detalhes que são pré-estabelecidos pela equipa responsável pela implementação do formatador e que podem diferir de uns para os outros. Por exemplo, os algoritmos que gerem a quebra de linha e de página podem ser implementados de várias maneiras.
Estes dois processos, transformação e formatação, podem constituir uma só aplicação ou, poderão ser duas aplicações completamente independentes. Não há qualquer dependência entre eles.
6.2.3. Linguagem de Transformação
Como já foi referido, a linguagem de transformação permite especificar processos de modificação (alteração/eliminação/criação).
Um processo de transformação pode compreender operações como:
Rearranjo de estruturas - reordenação e/ou agrupamento de estruturas existentes.
Construção de novos elementos relacionados com outros elementos já existentes - o analista especifica como é que os novos elementos se obtêm a partir dos existentes - por exemplo, as footnotes que vão aparecendo podem ser agrupadas e colocadas no fim do respectivo capítulo.
Associação de novas características a sequências específicas de conteúdo - o primeiro parágrafo de um capítulo pode ter um início diferente dos outros parágrafos nesse capítulo - estas sequências de conteúdo podem ser identificadas recorrendo à utilização de SDQL.
Associação de novas características a componentes específicos de conteúdo - por exemplo, associar atributos de formatação a strings do texto que não se encontram anotadas em SGML.
Resumindo, com esta linguagem o utilizador pode especificar modificações que afectam, quer o conteúdo, quer a estrutura do documento SGML original.
Como se disse acima, todas as operações especificadas no processo de transformação são independentes do processo de formatação que se lhe vai seguir.
6.2.4. O Processo de Transformação
O processo de transformação, SGML Tree Transformation Process (STTP), representado na Figura 6-2, compreende as etapas, que se descrevem a seguir: Construção do grove (Secção 6.2.4.1); Transformação (Secção 6.2.4.2); Geração de SGML (Secção 6.2.4.3).
6.2.4.1. Construção do grove
O documento SGML é submetido a um parser que vai reconhecer a sua estrutura e que o vai guardar numa estrutura interna especial - o grove. Um grove é a representação em grafo da estrutura e conteúdo de um documento; trata-se de um grafo orientado e pesado em que cada nodo é fortemente tipado (cada nodo tem uma etiqueta associada que responde pelo seu tipo: no Exemplo 6-1, há nodos do tipo receita, titulo, ...) e relaciona-se de várias maneiras com os seus vizinhos (pode-se ver uma relação como o peso associado a um ramo, no Exemplo 6-1 existem as relações: filho/conteúdo, irmão, atributos). Deste modo, a estrutura pode ser atravessada de diferentes formas, de acordo com o fim em vista. Pode-se por exemplo, realizar pesquisas contextuais do tipo: "Dê-me todas as receitas cujo título contem a palavra BOLO"; ou operações de filtragem do tipo: "Lista de todos os títulos de receita".
A estrutura utilizada nas ferramentas mais completas, como o jade [Cla96b], é bastante complexa; no entanto, depois de alguma experimentação prática nalguns projectos de publicação electrónica[1], concluiu-se que a estrutura mínima para representar um documento estruturado seria a seguinte (usa-se a notação CAMILA já apresentada):
Grove : Nodo-Seq
Nodo : identificador * Atributos * Conteúdo
| identificador * texto
Atributos : Atributo-Seq
Atributo : identificador * tipo * valor
Conteúdo : Nodo-SeqApresenta-se a seguir um exemplo prático de um grove (Exemplo 6-1).
Exemplo 6-1. Grove - estrutura para manipulação de documentos SGML
Eis uma instância de um documento SGML muito simples a partir do qual se irá construir o grove:
<RECEITAS>
<TITULO> O Meu Livro de Receitas </TITULO>
<RECEITA ORIGEM="Portugal">
<TITULO> Bolo </TITULO>
<INGREDIENTE> 500g de farinha </INGREDIENTE>
<INGREDIENTE> 200g de açucar </INGREDIENTE>
<INGREDIENTE> 300g de manteiga </INGREDIENTE>
</RECEITA>
</RECEITAS>O qual foi escrito de acordo com o seguinte DTD:
<!DOCTYPE RECEITAS [
<!ELEMENT RECEITAS (TITULO,RECEITA*)>
<!ELEMENT TITULO (#PCDATA)>
<!ELEMENT RECEITA (TITULO,INGREDIENTE+)>
<!ELEMENT INGREDIENTE (#PCDATA)>
<!ATTLIST RECEITA
ORIGEM CDATA #IMPLIED>
]>Na figura abaixo apresenta-se o grove correspondente ao documento apresentado em cima.
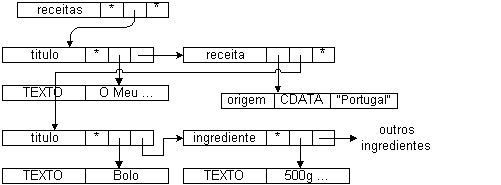
Os nodos com o identificador TEXTO são nodos com conteúdo documental, ao contrário dos outros que contêm informação estrutural.
Pode-se também ver as relações acima faladas: a primeira posição do tuplo que representa cada um dos nodos do grafo corresponde ao identificador do tipo de nodo, a segunda posição ao ramo correspondente à relação atributos, a terceira ao ramo correspondente à relação filho e a quarta ao ramo correspondente à relação irmão.
Em groves mais complexos, é normal aparecerem representadas as relações inversas (é apenas uma decisão de implementação e está relacionada com a eficiência de algumas operações.
Para mais informação o leitor pode consultar o texto da norma [Cla96] ou o já citado livro de DSSSL que está a ser escrito com as contribuições de todos através da Internet [Mul98].
6.2.4.2. Transformação
A Transformação propriamente dita é o cerne desta primeira fase sendo realizada por um sistema de tradução que vai reescrevendo a informação de cada nodo de acordo com regras Condição-Acção: uma regra é activada (seleccionada) sempre que a respectiva Condição sobre o nodo corrente (da travessia que o processo está a realizar) tiver o resultado verdadeiro; então a Acção é executada (normalmente corresponde a uma transformação do conteúdo do nodo corrente cujo resultado é enviado para a saída).
A especificação das operações de transformação é utilizada para controlar este processo que parte do grove do documento inicial e o transforma no grove do documento final.
A especificação de transformação é composta por um conjunto de associações. Cada associação é um triplo: uma expressão de query (para seleccionar os componentes do documento que irão ser afectados pela transformação) - aqui usa-se a referida SDQL; uma expressão de transformação - aqui usa-se Scheme; e uma expressão de prioridade, que é opcional (não se usa na maior parte dos casos).
Em CAMILA pode-se definir uma especificação de transformação da seguinte forma:
Espec-Transf : Associação-Set Associação : Exp_Selecção * Exp_Transformação *Exp_Prioridade
Devido à complexidade e dimensão do assunto remete-se o leitor para as referências já habituais [Cla96, Mul98] e apresenta-se a seguir um exemplo comentado de uma das transformações mais simples, a Transformação Identidade, que copia para a saída o conteúdo do grove.
Exemplo 6-2. A Transformação identidade
; Transformação identidade
; cria um novo grove igual ao primeiro
;
(=> (tudo) (transf-por-defeito))
; em que tudo é a Exp-Selecção
(define (tudo)
(subgrove (current-root)))
; em que transf-por-defeito é a Exp-Transformação
(define (transf-por-defeito)
(if (occurrence-mode (current-node))
(transf-por-origem)
(create-root #f (copy-current))))
(define (transf-por-origem)
(create-sub
(origin (current-node))
(copiar-actual)
(property: (occurrence-mode (current-node)))))
(define (copiar-actual)
(subgrove-spec node: (current-node)))Algumas legendas sobre as funções utilizadas:
- subgrove
devolve todos os descendentes de um nodo na forma de uma lista.
- current-node
devolve uma lista singular contendo o nodo que está a ser objecto da transformação.
- subgrove-spec
o subgrove que está a ser criado é descrito utilizando um objecto do tipo subgrove-spec. O argumento node: especifica qual a raiz do subgrove que está a ser criado.
- create-root
recebe como argumentos um identificador e um objecto do tipo subgrove-spec e especifica a criação da raiz do grove final.
- create-sub (origin...)
especifica a criação de um subgrove no grove final com a origem especificada pelo argumento origin.
6.2.4.3. Geração de SGML
Esta fase é normalmente realizada por um gerador que faz uma travessia em profundidade (descendente, da esquerda para a direita) ao grove enviando para a saída o seu conteúdo em formato SGML. O documento SGML resultante pode, depois, ser passado a um formatador, ou usado para intercâmbio com outras aplicações.
6.2.5. Linguagem de Estilo
A linguagem de estilo permite descrever a aparência visual desejada para o documento final através da especificação do processo de formatação.
O processo de formatação vai:
aplicar estilos de apresentação ao conteúdo do documento original e irá determinar a sua posição real na organização física das páginas.
seleccionar e reordenar o conteúdo do documento final tendo em conta a sua posição no documento original.
incluir material que não estava explicitamente presente no documento original - exemplo: geração de um índice.
excluir, do documento final, material presente no documento original.
Uma especificação de estilo é composta por um conjunto de regras de construção. O objectivo destas regras é a construção de uma nova estrutura, a Flow Object Tree (FOT). A FOT é uma árvore de objectos gráficos que funciona de representação intermédia para o processo de formatação. A especificação de estilo acaba por ser a especificação da transformação de uma árvore, o grove, noutra árvore, a FOT. Os objectos gráficos, que correspondem aos nodos da FOT encontram-se definidos na norma [Cla96]; no resto desta secção apresentam-se exemplos envolvendo a criação de alguns deles.
Actualmente o DSSSL suporta cinco tipos de regras de construção: root, element, default, query e id. Umas são mais específicas que as outras. Se fossem ordenadas da mais para a menos específica obter-se-ia a seguinte ordem: query, id, element, default, root. A prioridade de uma regra serve para resolver conflitos, por exemplo: se um elemento do grove for seleccionado por uma regra do tipo element então, a regra default já não se aplicará àquele elemento.
6.2.5.1. Estrutura das Regras de Construção
Em DSSSL, as regras de construção seguem a estrutura genérica que se apresenta a seguir:
(nome-da-regra (exp-selecção)
(exp-acção)
)A exp-selecção serve para seleccionar os nodos do grove aos quais será aplicada a exp-acção. Cada exp-acção está normalmente associada à construção de um nodo da FOT. Cada nodo da FOT pertence a uma classe de objectos gráficos. Cada classe tem a ela associados uma série de atributos que vão determinar a aparência visual dos respectivos objectos.
O DSSSL possui um conjunto de classes base e dá ao utilizador a possibilidade de definir outras.
Apresentam-se a seguir vários exemplos de regras de construção.
Exemplo 6-3. Regra associada ao documento
(root
(make display-group
(process-children)
)
)Aqui, root corresponde ao nome da regra, a expressão de selecção encontra-se omissa e a acção corresponde à invocação da função make.
A acção process-children indica que se pretende aplicar o resto da especificação aos descendentes deste nodo. Sem esta indicação o documento seria truncado a partir deste nodo.
Exemplo 6-4. Regra associada a todos os elementos no documento original
(default
(process-children)
)Neste exemplo, default corresponde ao nome da regra, a expressão de selecção é omissa e a acção corresponde à invocação da função process-children.
As duas regras apresentadas em cima fogem ao caso genérico ao não terem a expressão de selecção. Isto deve-se ao facto de essa expressão estar subjacente ao tipo de regra. No primeiro caso, regra de construção root, a regra, se estiver presente, é sempre seguida, mas apenas uma vez, quando o elemento a processar é a raiz do grove, que representa todo o documento. No segundo caso, regra de construção default, a regra é seguida para todos os nodos elemento, excepto quando estes são seleccionados por outra regra (lembrar a especificidade).
Exemplo 6-5. Regra associada a uma classe de elementos
(element (seccao titulo)
(make paragraph
font-family-name: "Helvetica"
font-weight: 'bold
(process-children)
)
)A expressão de selecção (seccao titulo) indica que esta regra será usada para processar nodos titulo que são filhos de nodos seccao. Esta regra ficará associada a todos os elementos do documento que pertençam a esta classe. Outros nodos titulo, que não dentro de secção, não serão associados a esta regra.
Exemplo 6-6. Regra associada a um elemento específico identificado por um atributo do tipo ID
(id ("sec2")
(make paragraph
font-family-name: "Helvetica"
font-weight: 'bold
(process-children)
)
)Ao contrário da regra anterior, esta fica associada apenas a uma instância de um elemento, àquele que tiver um atributo do tipo ID com valor igual ao indicado na expressão de selecção - "sec2".
Exemplo 6-7. Regra associada a uma 'query'
(query q-class 'pi
(make paragraph
literal "Instrução de Processamento:"
(node-property 'system-data (current-node))
)
)Esta regra permite seleccionar todos os elementos abrangidos pela expressão de selecção. Neste caso, a expressão de selecção 'pi indica que se pretende seleccionar todas as "Processing Instructions". Devido à grande complexidade que levanta na sua implementação, não foi implementada nos processadores de DSSSL actualmente disponíveis.
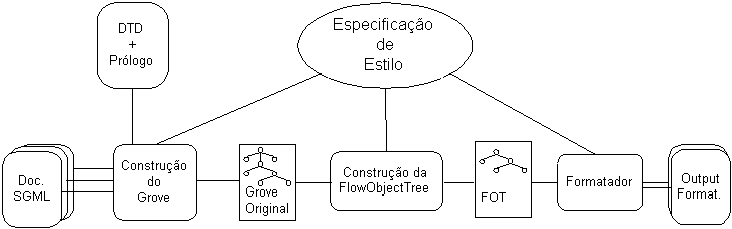
6.2.6. O Processo de Formatação
Tal como se disse atrás para o caso da transformação, antes do início do processamento o documento tem que ser analisado e uma estrutura arbórea tem que ser criada com o seu conteúdo - o grove: se o processo de formatação se seguir a uma transformação o grove encontra-se já disponível; senão, terá de se começar pelo parsing do documento fonte. Como já se mostrou, cada nodo desta estrutura corresponde a um elemento do documento. O processo de formatação especifica-se associando a cada nodo do grove um conjunto de regras de construção que irão criar uma nova estrutura - a Flow Object Tree (FOT). Nesta nova estrutura, cada um dos nodos corresponde a um objecto com características gráficas. Para finalizar o processo, esta estrutura é passada a um formatador que apenas vai organizar espacialmente, no suporte físico de saída seleccionado, os objectos gráficos.
Assim e resumindo, o processo de formatação, que se vê esquematizado na Figura 6-3, compreende três fases:
- Construção do grove
O documento SGML é submetido a um parser que o vai validar e produzir um grove (como no processo de transformação).
- Construção da Flow Object Tree
O grove é submetido a um processo que lhe vai aplicar as regras de construção especificadas na especificação de estilo e assim gerar a Flow Object Tree.
- Formatação
O formatador parte da Flow Object Tree, aplica as suas regras geométricas, faz a composição dos vários objectos gráficos pertencentes à Flow Object Tree e produz o documento final.
6.2.7. Algumas especificações exemplo
Apresentam-se agora algumas especificações DSSSL que, se fossem utilizadas para processar o livro de receitas do Exemplo 6-1, serviriam para obter os efeitos indicados em cada caso.
Comecça-se por uma especificação de estilo básica que simplesmente converterá o texto do documento SGML original para RTF, MIF, ou TeX (conforme a opção passada ao formatador), sem nenhum requisito de formatação.
Exemplo 6-8. Especificação de Estilo básica
(root
(make simple-page-sequence
(process-children))
)make é uma função que constrói um nodo da FOT; neste caso um nodo da classe simple-page-sequence.
um nodo do tipo simple-page-sequence vai fazer com que seja produzida uma sequência de áreas de página.
a função process-children dá a indicação de que o processamento deverá continuar para os descendentes do nodo que se está a processar.
Complica-se, agora, o exemplo anterior, adicionando à especificação as indicações necessárias para formatar as margens do texto.
Exemplo 6-9. Adicionando margens
(root
(make simple-page-sequence
left-margin: 3cm
right-margin: 2cm
top-margin: 3cm
bottom-margin: 3cm
(process-children))
)O objecto simple-page-sequence tem uma série de atributos que permitem descrever a formatação do seu conteúdo. Neste caso utilizam-se os atributos relativos às dimensões das páginas.
Complicando mais um pouco, pretende-se agora formatar de maneira diferente o título do livro de receitas e o título individual de cada receita.
Exemplo 6-10. Formatando os títulos
(element (RECEITAS TITULO)
(make paragraph
quadding: 'center
font-size: 18pt
keep-with-next?: #f
(process-children)
)
)
(element (RECEITA TITULO)
(make paragraph
quadding: 'left
font-size: 16pt
keep-with-next?: #f
(process-children)
)
)As expressões de selecção associam respectivamente uns atributos a um e ao outro tipo de título.
A classe paragraph é geralmente utilizada para elementos do tipo bloco, que se individualizam dos elementos que o precedem e que lhe sucedem.
A especificação anterior pode ser reescrita recorrendo à utilização de variáveis para os valores dos atributos, o que facilitará a sua manutenção.
Exemplo 6-11. Adicionando variáveis para facilitar a manutenção
;Constantes
(define *tituloPrinc* 18pt)
(define *tituloReceita* (- *tituloPrinc* 2))
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
(element (RECEITAS TITULO)
(make paragraph
quadding: 'center
font-size: *tituloPrinc*
keep-with-next?: #f
(process-children)
)
)
(element (RECEITA TITULO)
(make paragraph
quadding: 'left
font-size: *tituloReceita*
keep-with-next?: #f
(process-children)
)
)Desta maneira, a modificação do tamanho da fonte só necessita de ser feita num local, o que facilita enormemente a manutenção.
Aqui estão a ser utilizados alguns dos muitos atributos da classe paragraph. Para uma informação mais detalhada sobre as classes e respectivos atributos aconselha-se a leitura da norma.
Por fim, mostra-se um exemplo que exibe o tipo de especificação utilizada para a criação de índices e outros tipos de listas de conteúdos. Neste caso, coloca-se no início do livro de receitas uma lista de todos os ingredientes necessários para a execução de todas as receitas - isto implica uma passagem adicional sobre o documento para a construção desta lista.
Exemplo 6-12. Utilizando mais de uma passagem sobre o documento
(element RECEITAS
(make sequence
(literal "Ingredientes necessários:")
(make paragraph
(with-mode *ingredientes*
(process-matching-children "INGREDIENTE")))
(process-children)
)
)
(mode *ingredientes*
(element INGREDIENTE
(if (= (child-number) 1)
(make sequence
font-posture: 'italic
(process-children))
(make sequence
font-posture: 'italic
(literal " & ")
(process-children))))
(default
(empty-sosofo)))Cada passagem sobre o documento tem a designação de mode. Se nada for declarado o processamento é realizado em normal-mode; para processamentos adicionais outros mode terão de ser criados - neste caso criou-se o mode ingredientes.
Nesta secção, deu-se uma ideia da potencialidade do DSSSL e da metodologia de especificação que lhe é subjacente. Muita coisa ficou fora desta abordagem, no entanto, as características aqui apresentadas permitem concretizar processos de formatação com alguma complexidade.
A Semântica Estática é um assunto completamente novo. Até à data, não houve nenhum estudo que apontasse uma solução para a sua definição e implementação. Neste momento, existem umas propostas em estudo [DCD, WIDL] a nível do World Wide Web Consortium (W3C) - entidade que superintende a criação de novas normas relacionadas com a publicação electrónica e a Internet, mas numa forma ainda muito incipiente.
Como a discussão desta temática reflecte a contribuição mais significativa desta tese, é apresentada num capítulo à parte, o próximo, Capítulo 7.