Capítulo 7. Validação Semântica em Documentos SGML
7.1. Semântica Estática
A introdução do SGML trouxe uma nova abordagem ao processamento documental: validação estrutural automática, validação em tempo real durante a edição (o autor está sempre informado sobre a correcção ou incorrecção estrutural do documento que está a produzir), independência face a plataformas de software e hardware.
Na figura seguinte mostra-se este modelo de trabalho, que não é mais do que um subconjunto do ciclo de vida apresentado na Capítulo 5.
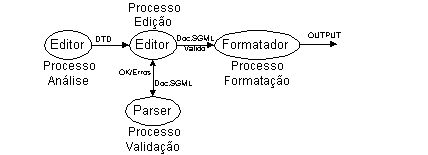
7.1.1. Qual é o problema?
O modelo apresentado é suficiente para uma grande parte das aplicações do SGML. No entanto, quando se trabalha um certo tipo de informação há uma grave lacuna: validação semântica. Por exemplo, imagine-se que alguém está a produzir um CD-ROM com conteúdo histórico; um erro na data de nascimento de um rei ou uma associação cronológica com o reinado mal feita pode fazer colapsar todo o projecto.
Relativamente à consistência e correcção da informação, o SGML assegura uma validação estrutural completa e alguma validação semântica (através da associação de atributos aos elementos); é possível garantir que um determinado atributo tem um valor dentro de um conjunto de possibilidades. Mas, quando se trabalha com documentos com conteúdos mais ricos é preciso colocar restrições mais fortes sobre esses conteúdos; esta necessidade está para além das capacidades do SGML.
Esta lacuna tornou-se evidente quando se avançou na implementação de projectos reais (descritos mais à frente em Apêndice B). Nesses projectos, trabalhou-se com o Arquivo Distrital de Braga e com o Departamento de História da Universidade do Minho. Pretendia-se disponibilizar grandes volumes de informação na Internet e trabalhá-la de modo a ser possível gerar também outras formas: CD-ROM, papel, ... Para tal montou-se uma linha editorial baseada em SGML. Um dos problemas críticos era o tempo e aqui começou a sentir-se a falta de uma validação semântica automática que, como era inexistente, levou a que se implementasse uma série de ciclos de revisão, o que atrasou (e ainda atrasa) os projectos na sua fase final de divulgação da informação.
Nas secções seguintes, não se apresenta uma solução completa para o problema da validação semântica. A solução desenvolvida tratará um subconjunto de problemas da validação semântica: a restrição do conteúdo textual (#PCDATA) de um determinado tipo de elemento e a verificação das relações entre subelementos e atributos.
Para exemplicar estas ideias apresentam-se a seguir dois casos de estudo. Estes dois casos emergem dos projectos acima referidos, onde se está a colectar informação de várias fontes, que depois de processada é distribuída via Internet. Os problemas apontados são simples e seriam facilmente resolvidos se houvesse alguma maneira de expressar restrições no modelo.
7.1.1.1. Registos Paroquiais
No contexto da demografia histórica, a fonte de informação são os registos das paróquias, que até ao início do século XX funcionaram como registos civis. Numa comunidade católica, o pároco mantém um registo dos eventos realizados na paróquia: casamentos, baptismos, funerais, ... Há, portanto, vários tipos de documentos: certidões de casamento, de baptismos, de óbito e ainda outros que não se encaixam numa classificação deste tipo.
O que se pretende aqui, é reunir aquela informação documental e construir uma base de dados de indivíduos com as respectivas relações familiares. Esta base de dados poderá depois fornecer informação para a construção de modelos estatísticos que registarão a evolução de hábitos e costumes permitindo que cada um de nós possa aprender um pouco mais sobre as suas raízes.
Imagine-se agora, que temos uma equipa a introduzir aqueles documentos no computador em formato SGML (os originais estão bastante deteriorados e são demasiado irregulares na estrutura para permitirem uma digitalização automática). As pessoas, por vezes, cometem erros nas transcrições. O parser de SGML detecta os erros de sintaxe/estruturais. Os outros, erros semânticos, passam indetectados e poderão levar a vários problemas que influenciarão os modelos estatísticos que se pretendem criar. Por exemplo:
idades ao casamento negativas - provavelmente foi introduzida uma data errada num dos certificados.
morte antes do baptismo - o mesmo problema retratado acima.
casamentos entre pessoas com uma diferença de idades superior a 100 - um dos elementos do casal deve ter uma data a ele associada que foi mal introduzida.
Todos estes problemas podiam ser resolvidos com restrições simples sobre o domínio de valores: "data de nascimento deve ser sempre maior que data de morte"; relativamente a casamentos, "a diferença das datas de nascimento dos conjugues deverá ser sempre menor que um determinado valor", etc.
7.1.1.2. Arqueologia
Outra fonte de informação com quem se trabalhou é a Unidade de Arqueologia da Universidade do Minho.
Esta equipa de arqueólogos tem produzido uma série de documentos SGML que retratam arqueosítios e artefactos. Na estrutura destes documentos há 2 elementos que têm de estar presentes obrigatoriamente e que dizem respeito à localização geográfica da entidade descrita: latitude e longitude. À medida que cada documento é produzido pretende-se associá-lo a um ponto num mapa, construindo desta forma um Sistema de Informação Geográfica (SIG).
Uma coisa que se deve garantir é que cada par de coordenadas cai dentro do mapa, dentro de um certo intervalo. Isto, não pode ser feito usando apenas SGML. Mas uma linguagem simples onde se pudessem expressar restrições sobre um dado domínio serviria.
7.1.2. Restrições e condições de contexto
Há um problema para resolver. É necessário impôr condições sobre o conteúdo de alguns elementos e que o sistema tenha capacidade para verificar essas condições. Para isso, tem que se adicionar restrições aos documentos SGML, o que traz algumas implicações e levanta outros problemas: normalização de conteúdos, associação de tipos aos conteúdos, que linguagem utilizar para definir as restrições e como processá-las.
Como já foi referido, não se pode utilizar a sintaxe do SGML para expressar restrições ou invariantes sobre o conteúdo dos elementos que compõem o documento. O SGML foi criado como uma metodologia para especificação de estrutura e, na área da validação estrutural, o grande número de ferramentas disponíveis faz dele uma forte e poderosa metodologia de especificação.
Se o que se pretende para salvaguardar a semântica dos documentos é restringir conteúdos, precisa-se de facto de adicionar essa capacidade ao SGML. Para isso, existem várias hipóteses: pode-se simplesmente adicionar sintaxe extra ao SGML; ou desenhar uma nova linguagem a embeber no SGML ou a coexistir fora dele. A adição de sintaxe extra implicaria a modificação de todas as ferramentas existentes para que estas reagissem à nova estensão ou simplesmente a ignorassem. O custo desta solução seria enorme; por isso segue-se o outro caminho: a definição de uma linguagem que permita a especificação de restrições sobre elementos em documentos SGML.
Até ao momento, as restrições que houve necessidade de impôr são bastante simples. Na maioria dos casos, apenas se pretende restringir o valor de elementos atómicos a um domínio, verificar uma relação entre elementos, ou verificar se um determinado conteúdo está coerente com a informação guardada numa base de dados de suporte. Uma das razões para isto acontecer é a validação estrutural já realizada pelo SGML ser tão forte que apenas deixa o conteúdo dos elementos de fora.
Pode parecer, portanto, que uma linguagem simples resolve o problema. No entanto, pode-se desde já distinguir duas fases importantes neste processo:
a definição - a parte sintáctica do modelo de restrições, as declarações que expressam as restrições.
o processamento - a parte semântica do modelo de restrições, a sua interpretação.
Estas duas fases têm objectivos diferentes e correspondem também a diferentes níveis de dificuldade na sua implementação. A primeira envolve a criação de uma linguagem, ou a adopção de uma existente. Para a fase de processamento, torna-se necessário implementar um motor que seja capaz de avaliar e reagir às declarações escritas na linguagem de restrições. Para implementar este motor será preciso associar tipos à informação com toda a complexidade que lhes é inerente.
Neste momento, pode-se ser tentado a questionar esta complexidade: "Não se poderá sobreviver sem tipos?". Considere-se o seguinte exemplo extraído do segundo caso de estudo (Secção 7.1.1.2):
Exemplo 7-1. SGML com restrições
SGML Document
<latitude>41.32</latitude>
Restrição
latitude > 39 and latitude < 43Neste exemplo, pretende-se garantir que o valor introduzido no elemento latitude de um arqueosítio está compreendido dentro de certos valores. Está-se a verificar se um determinado valor está dentro de um domínio. Está-se a comparar o conteúdo do elemento latitude com valores numéricos que têm um tipo inerente (inteiro ou real). Assim, o motor que vai executar esta comparação irá ter de inferir um tipo para o conteúdo do elemento latitude que está a ser comparado.
Exemplos como este são muito simples. O conteúdo numérico de um elemento tem uma forma mais ou menos normalizada (pode ser expressso por uma expressão regular). Mas há outros bem mais complexos, como a data: há imensas maneiras diferentes de escrever uma data (e provavelmente qualquer um de nós pode facilmente inventar mais uma).
Noutro caso de estudo, um trabalho realizado para o Arquivo Distrital de Braga [Fig98], trabalha-se com documentos do século XVII e XVIII; nesses documentos, o nome "Afonso Henriques", o primeiro rei português, aparece escrito de duas maneiras diferentes: "Afonso" e "Affonso". E ainda há outros personagens que são referenciados de mais de duas maneiras distintas. Para se poder impôr restrições ao nome dos reis de Portugal, há que saber o tipo desses elementos e de usar um valor independente da ortografia.
Vai-se designar este problema por problema de normalização. Para além desta situação de imposição de restrições, a normalização torna-se crítica quando se pretende construir índices sobre os documentos, para alimentar motores de busca ou simplesmente para implementar mecanismos de acesso à informação. O computador precisa de entender que textos diferentes são referências para o mesmo objecto.
Por agora, propõem-se duas soluções para resolver os problemas da normalização e da inferência de tipos:
desenvolver e implementar uma linha de ferramentas, com alguma complexidade, que resolverão os problemas, primeiro a normalização, depois a inferência de tipos.
introduzir algumas modificações no DTD que resolverão o problema da normalização e reduzirão a inferência de tipos a um problema mais simples.
Obviamente, é a segunda que deve ser seguida. Não só porque é mais simples, mas também porque o problema da normalização tem atraído a atenção de investigadores, principalmente na área da História, o que fez com que várias aproximações a uma boa solução tivessem surgido. Uma das melhores e a mais utilizada no momento é a proposta do "Text Encoding Initiative (TEI)" [SB94]. A solução é bastante simples, basta adicionar um atributo de nome "value" (no caso presente designa-se esse atributo por "valor") aos elementos cujo conteúdo levantará problemas de normalização. A ideia é a do conteúdo do elemento poder tomar qualquer forma, desde que o atributo "valor" seja preenchido com o valor normalizado.
Exemplo 7-2. Normalização via adição de um atributo
... perdeu a batalha no <data valor="1853.10.05">
quinto dia do mês de Outubro do ano 1853 </data> ...Neste exemplo, convencionou-se que o formato normalizado para as datas seria o ANSI (ano.mês.dia).
Esta solução, pressupõe uma análise prévia do conteúdo documental, que pode ser feita antes ou depois da edição do documento em SGML. Durante essa análise deverão ser levantados todos os problemas de normalização para que depois ou durante a edição do documento SGML se adicione, aos elementos críticos, o atributo "valor" com o valor convencionado.
Em trabalhos publicados durante a realização desta tese [RRAH99], propôs-se uma solução semelhante para simplificar a inferência de tipos. A todos os elementos que irão ter a eles associada uma restrição é adicionado um atributo de nome "type" ("tipo" na implementação portuguesa) cujo valor é a designação do tipo de dados que se quer associar aos elementos em causa.
Aplicando estas duas soluções aos exemplos discutidos durante esta secção o resultado seria o seguinte:
- [latitude]
<latitude tipo="real"> 41.32 </latitude> ...
- [datas]
... aconteceu no <data tipo="date" valor="1853.10.05">quinto dia do mês de Outubro do ano 1853 </data> ...
- [nomes]
... naquele ano <nome valor="Afonso"> Affonso </nome> proclamou vários decretos ...
Assume-se que, quando um atributo "valor" não se encontra instanciado, o conteúdo do elemento respectivo já se encontra na forma normalizada.
Relativamente ao atributo "tipo", a sua colocação levanta alguns problemas. Normalmente, o analista que desenvolve o DTD e o utilizador que vai usar esse DTD para editar os seus documentos são pessoas diferentes, com níveis de conhecimento técnico diferentes. E, este atributo faz com que o utilizador tenha que saber o que são tipos de dados, quais os tipos de elementos que irão ter restrições sobre eles (só esses necessitam de ser "tipados") e que instancie correctamente este atributo para estes elementos. O ideal seria que apenas o analista se preocupasse com este aspecto e tudo isto fosse transparente para o utilizador. O SGML tem uma característica que nos permite implementar esta separação: os atributos do tipo "#FIXED".
Sempre que houver um elemento com um determinado atributo de valor constante e não se quiser que o utilizador altere esse valor, esse atributo deve ser declarado como #FIXED no DTD onde o respectivo valor deverá também ser declarado.
Voltando ao exemplo das latitudes:
Exemplo 7-3. Atributos "#FIXED"
DTD
...
<ELEMENT latitude - - (#PCDATA)>
<ATTLIST latitude tipo CDATA #FIXED "real">
...tipo é o nome do atributo.
CDATA é o tipo do valor do atributo, neste caso, indica que será uma string.
#FIXED é o valor por omissão do atributo; indica ao sistema que no caso do utilizador não o ter instanciado o sistema deverá assumir o valor fornecido na declaração, por outro lado, se o utilizador instanciar o atributo o sistema deverá garantir que este é idêntico àquele que foi fornecido na declaração.
"real" é o valor do atributo.
Ao trabalhar com um documento que esteja a ser criado com o DTD exemplificado acima, o sistema, em todas as operações que envolvam o processamento SGML (por exemplo na exportação do documento para o sistema), acrescentará um atributo "tipo" a todos os elementos "latitude" com valor "real". Qualquer tentativa do utilizador para instanciar aquele atributo com outro valor será ignorada pelo sistema. Desta maneira, a associação de tipos aos elementos tornou-se transparente para o utilizador, até mesmo inacessível.
A adição destes dois atributos a um ou a vários elementos levanta alguns problemas nas futuras transformações que se pretendam implementar sobre o documento. No caso do atributo valor, há situações em que se pretende utilizar o valor normalizado (por exemplo numa procura, ou na construção de um índice) e outras, em que se pretende utilizar o valor original (por exemplo numa publicação fiel ao documento original).
Uma questão relevante pode agora ser levantada: Será que é necessário associar um tipo a todos os elementos? Ou apenas a elementos atómicos (aqueles cujo conteúdo é apenas #PCDATA)?
A questão levantada aparenta ser simples com uma resposta binária de sim ou não. No entanto, qualquer uma das respostas traz consigo um certo peso.
Uma resposta afirmativa implicaria que para além de tipos atómicos de dados, o sistema, suportasse tipos estruturados que seriam associados aos nodos intermédios da árvore documental. Desta maneira, haveria um mapeamento completo entre a estrutura do documento e o modelo abstracto de tipos. As respectivas consequências desta abordagem, vantagens e desvantagens, seriam:
o sistema de tipos fica mais complexo.
os tipos estruturados seriam mais facilmente inferidos do DTD do que do conteúdo dos elementos; isto implicaria a criação de uma ferramenta de conversão.
um mapeamento completo entre a estrutura do documento e um modelo abstracto de tipos de dados permitiria o processamento do documento no sistema de suporte do modelo abstracto; o que implicaria a criação e a utilização de ferramentas poderosas (estas ferramentas resultariam da combinação dos operadores algébricos do sistema de suporte do modelo abstracto).
Por outro lado, se se decidir associar um tipo de dados apenas a alguns elementos atómicos (algumas folhas da árvore documental), podem-se prever as seguintes consequências:
a linguagem de restrições seria muito simples; reduzida a operações lógicas sobre tipos atómicos de dados e algumas funções de interrogação.
o motor de processamento resultaria simples e por isso fácil de implementar.
o modelo abstracto estaria incompleto; ficaríamos com um conjunto de pequenos bocados do modelo completo; isto tornaria inviável qualquer processamento do documento no sistema de suporte do modelo abstracto.
Em defesa deste último ponto de vista pode-se ainda apontar o seguinte: o SGML é puramente declarativo ("declarative markup"); serve para definir estruturas; estas estruturas não são mais nem menos do que os tipos estruturados que temos vindo a discutir. Assim, pode-se afirmar que os tipos estruturados são intrínsecos aos documentos; a respectiva validação é feita quando o documento é analisado e portanto não será necessário complicar a linguagem de restrições para realizar esta tarefa. Para clarificar este ponto, veja-se o próximo exemplo: descreve-se em SGML uma árvore binária que neste caso modela uma árvore genealógica.
Exemplo 7-4. Uma árvore binária
O respectivo DTD (a declaração da estrutura de dados) define-se da seguinte maneira:
<!DOCTYPE arv-bin [
<!ELEMENT arv-bin - - (nodo)>
<!ELEMENT nodo - - (valor,filhos?)>
<!ELEMENT valor - - (#PCDATA)>
<!ELEMENT filhos - - (nodo?,nodo?)>
]>O leitor atento reparará que se introduz um nível de redundância na especificação ao declarar-se o elemento FILHOS como opcional e, depois, os seus descendentes NODO, de novo, como opcionais. Isso foi feito conscientemente devido às implicações que existiriam na escrita de instâncias se FILHO, fosse obrigatório (para nodos sem filhos o autor seria sempre obrigado a colocar a anotação FILHO apesar de depois não lhe introduzir nenhum conteúdo).
A figura seguinte apresenta uma árvore genealógica que a seguir é instanciada em SGML de acordo com o DTD apresentado.
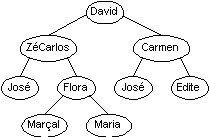
<arv-bin>
<nodo>
<valor>David</valor>
<filhos>
<nodo>
<valor>ZéCarlos</valor>
<filhos>
<nodo>
<valor>José</valor>
</nodo>
<nodo>
<valor>Flora</valor>
<filhos>
<nodo>
<valor>Marçal</valor>
</nodo>
<nodo>
<valor>Maria</valor>
</nodo>
</filhos>
</nodo>
</filhos>
</nodo>
<nodo>
<valor>Carmen</valor>
<filhos>
<nodo>
<valor>José</valor>
</nodo>
<nodo>
<valor>Edite</valor>
</nodo>
</filhos>
</nodo>
</filhos>
</nodo>Deste exemplo, pode-se concluir o seguinte: é possível definir tipos estruturados de dados de uma forma puramente declarativa; a semântica está nos tipos atómicos; se se ignorar os tipos atómicos ou, deixar ao sistema o trabalho de inferir o seu tipo, pode-se afirmar que as estruturas definidas em SGML correspondem a tipos estruturados de dados.
Num primeiro trabalho publicado no âmbito desta tese [RAH95], apresentou-se uma abordagem à primeira das direcções apontadas (associação de tipos a todos os elementos). Num trabalho posterior [RAH96], aquela abordagem foi refinada e um estudo comparativo com uma outra foi apresentado. Como resultado desse estudo, desenvolveram-se duas soluções para o problema do processamento da semântica estática. Cada solução seguiu uma abordagem formal diferente. São estas duas abordagens que se apresentam nos dois capítulos seguintes e que são respectivamente, uma abordagem via modelos abstractos (Capítulo 8) e uma abordagem via gramáticas de atributos (Capítulo 9).