Capítulo 8. Validação Semântica com Modelos Abstractos
Neste capítulo apresenta-se uma solução para o processamento de restrições semânticas, processamento esse a residir num ambiente externo ao da aplicação SGML. A ideia é criar uma solução compatível com as aplicações existentes, fazer com que o processamento das restrições se possa acoplar ao que já existe sem alterações das metodologias e ferramentas de trabalho.
Como se pode ver na figura seguinte (Figura 8-1), aquilo que se propõe aqui fazer é uma pequena adição ao modelo de processamento existente: um novo componente que não provocará nenhuma alteração dos outros componentes.
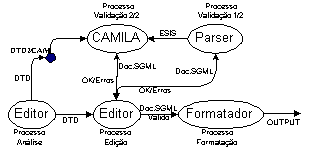
Na implementação deste componente e desta abordagem foi usada uma linguagem de especificação e um sistema de prototipagem com o mesmo nome, CAMILA, brevemente introduzidos num dos capítulos introdutórios (Capítulo 2). O CAMILA não é a única linguagem baseada em métodos formais. A sua escolha deve-se ao facto de ser linguagem desenvolvida e mantida no centro de investigação a que o autor pertence. À data em que esta abordagem começou a ser desenvolvida não havia outro projecto paralelo a utilizar métodos formais como abordagem ao processamento documental. Mais recentemente, surgiu um trabalho, muito semelhante ao que neste capítulo se apresenta, baseado na linguagem de programação funcional Haskell [Tho97b]. A principal diferença entre esse trabalho [WR2000] e o que a seguir se apresenta reside no facto do parser de SGML/XML ter sido incorporado no sistema desenvolvido. Na presente abordagem, uma das razões porque isso não acontece é a de que se pretendia criar um módulo de validação que se pudesse juntar à tecnologia existente.
Neste capítulo, apresenta-se a implementação do novo componente e o impacto e respectivas consequências no ciclo de vida da produção de documentos.
8.1. Modelos Abstractos: porquê?
Para ilustrar estas ideias utiliza-se um caso de estudo que é útil para demonstrar vários aspectos do problema: o tipo de documentos subjacente ao conceito "literate programming" [Knu92]. Este tipo de documentos foi criado para permitir a mistura, dentro do mesmo ficheiro, do código de um programa e respectivo manual/relatório. Para isso estão disponíveis anotações que permitem a identificação e o estabelecimento de relações entre aqueles dois tipos de componentes, de modo a que mais tarde seja possível extrair as partes relevantes: o programa para compilar ou o relatório para imprimir. Com efeito, nos exemplos que aparecem à frente, centra-se a atenção no procedimento de extracção e composição de programas a partir de um documento literate programming. Este procedimento servirá como termo de comparação das várias abordagens.
Assim, um documento em literate programming é um texto de conteúdo misto, composto por elementos especiais, código e definições. Uma definição é uma associação de um identificador a um pedaço de código ou texto; um programa pode incluir referências a estes identificadores.
Apresenta-se a seguir um exemplo de um DTD e respectiva instância documental para este tipo de documentos.
Exemplo 8-1. Literate Programming
O DTD que se segue define formalmente a estrutura de um documento do tipo literate programming.
<!DOCTYPE litprog [ <!ELEMENT litprog - - ((#PCDATA|prog|def|id|sec|tit)*)> <!ELEMENT prog - - ((#PCDATA|id)*)> <!ELEMENT def - - (prog)> <!ATTLIST def ident ID #REQUIRED> <!ELEMENT sec - - (#PCDATA)> <!ELEMENT tit - - (#PCDATA)> <!ELEMENT id - o EMPTY> <!ATTLIST id refid IDREF #REQUIRED> ]>
O texto seguinte é um exemplo concreto de um documento escrito de acordo com o DTD acima.
<litprog>
<tit>Exemplo de Literate Programming</tit>
<sec>Stack - FAQ</sec>
<def ident="main">
<prog>
main(){
int S[20]; sp=0;
<id refid="push">
<id refid="pop">
}
</prog>
</def>
<sec>Push</sec>
Esta função pode ser usada para colocar elementos
na stack.
<def ident="push">
<prog>void push(int x)
{S[sp++]=x;}
</prog>
</def>
</litprog>O texto em si é um manual de um determinado programa. Quando se produz um documento deste tipo há dois processamentos esperados: a produção do manual propriamente dito e a extracção do programa para se compilar. O extractor poderá retirar o programa ou parte dele, o utilizador indicará o que pretende passando o identificador da raiz da subárvore de pedaços de código que pretende extrair.
Nesta aproximação converte-se o documento num modelo abstracto de dados e utiliza-se o sistema de suporte desse modelo (neste caso o CAMILA) para especificar o processamento do documento.
Um DTD, do ponto de vista algébrico pode ser visto como um modelo, como já foi discutido em [RAH95]. Por exemplo, o caso de estudo apresentado pode ser modelado em CAMILA da seguinte forma:
model
type
litprog = X-seq
X = (TEXTO | prog | def
| id | sec | tit)
prog = Y-seq
Y = (TEXTO | id)
def = i:ID * p:prog
sec = TEXTO
id = ID
tit = TEXTO
endtypeA construção do modelo CAMILA foi feita sistematicamente seguindo a tabela de equivalência abaixo apresentada.
Tabela 8-1. Esquema de Tradução SGML ↔ CAMILA
| SGML | CAMILA |
|---|---|
| x,y | produto cartesiano |
| x & y | x * y | y * x |
| x | y | união disjunta |
| x* | x-seq |
| x+ | x * x-seq |
| x? | [ x ] |
Nesta abordagem, o processamento é especificado como uma função ou funções sobre o modelo abstracto. Por exemplo, o nosso extractor de programas getprogram(), será então expresso como uma função que recebe um documento do tipo literate programming, colecta todos os bocados de código nele espalhados, organiza-os de forma correcta, produzindo assim um programa, neste caso em C, do tipo cprog definido abaixo.
type
cprog = TEXTO-seq
endtypeEntão, o referido extractor poderia ser assim especificado:
func getprogram( d :litprog ) :cprog
returns explode('main,mkindex(t));A função getprogram() realiza uma substituição recursiva (explode) dos identificadores (id) pelos respectivos programas, começando pelo identificador main. O exercício fica completo com a definição das duas funções que faltam: explode() e mkindex().
func mkindex( d :litprog ) :id→prog return [i(x) → p(x) | x ← t : is-def(x) ];
A função mkindex recebe um documento e constrói uma função finita de identificador para excerto de código, é a função colectora. Esta função pressupõe que o argumento que lhe é passado foi bem construído, isto é, para que da sua execução não resulte uma função finita indefinida há que garantir a dependência funcional:
i(x) → p(x)que se pode traduzir no seguinte invariante:
<..., def("i",p1), ..., def("i",p2), ...> sse p1 = p2 A verificação deste invariante é feita pelo construtor do tipo litprog. func explode( i :id, d :id→prog ) :cprog
pre i in dom(d) → <>
returns( CONC( < if( is-id(x) → explode(x,d),
else → <x> ) | x ← d[i]> );A função explode recebe a função finita construída na função anterior, um identificador indicando qual a raiz da derivação e constrói o programa, é a função compositora.
Esta abordagem é boa para prototipar, quer estruturas, quer processamento. No caso específico dos documentos SGML, apresenta-se uma possível via de translacção do seu processamento para o nosso sistema algébrico. Há no entanto alguns pontos a refinar: o esquema de tradução tem de ser enriquecido, os modelos abstractos nos quais se mapearam os construtores do SGML são, regra geral, menos específicos, têm menor poder expressivo; assim, terão de ser restringidos via adição de um invariante de tipo para se conseguir manter a mesma semântica. A maior parte da especificidade do SGML resulta deste ter sido pensado para anotar texto. O texto tem uma ordem linear inerente. Esta ordem foi transportada para o SGML sob a forma dos operadores "&" e ",". Perante um DTD onde aqueles operadores existam, a sua conversão num modelo CAMILA necessitará da adição de invariantes que garantam a especificidade da ordem.
Podia-se ser levado a pensar se não valeria a pena criar um protótipo em CAMILA que suportasse o ciclo de vida do SGML. A ideia seria prescindir do parser e usar os construtores do CAMILA para especificar uma estrutura que depois seria preenchida com instâncias documentais às quais seriam aplicados processamentos sob a forma de execução de funções sobre o modelo algébrico. Isto seria possível se a equivalência semântica entre as duas notações de especificação fosse real. Como já foi discutido a notação CAMILA é mais lata, menos específica que o SGML e a criação deste sistema só seria possível via adição de vários invariantes e condições de contexto que no seu todo seriam semanticamente equivalentes a um parser SGML.