8.4. Processamento das Restrições
Depois de se ter discutido a inclusão/ligação de restrições aos DTDs, vai-se ver agora de que modo é que se pode acopular o módulo de validação extra a um sistema existente.
Como foi apresentado na Figura 8-1, adicionou-se um processo extra ao modelo de processamento baseado em SGML tradicional. Este novo processo será o responsável pela execução das tarefas necessárias à verificação das restrições.
Na Figura 8-2, pode-se ver este processo com mais detalhe.
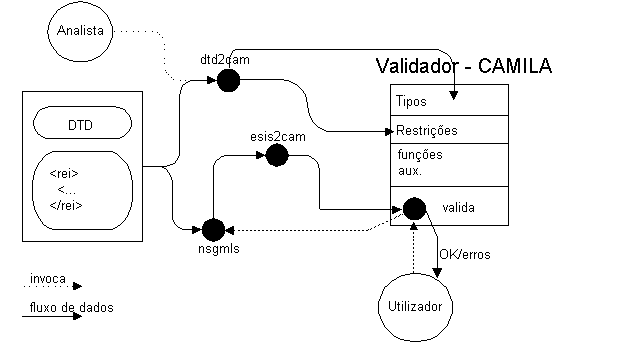
A adição deste novo processo exige adaptações a dois níveis: um relacionado com as pessoas intervenientes, analista e utilizadores, e outro relacionado com o software, como é que vão interactuar as novas rotinas com as já existentes. O primeiro nível será designado por operacional e o segundo por aplicacional e podem ser descritos da seguinte forma:
- Nível Operacional
Neste nível considera-se que há sempre a intervenção de dois tipos de agente: o analista e o autor.
No modelo tradicional (Figura 7-1), o analista apenas tinha que desenvolver o DTD. No novo modelo, além do DTD, o analista terá de desenvolver ao mesmo tempo a especificação de restrições.
No fim da fase de análise, uma cópia do DTD é enviada ao processo de edição e, a mesma cópia juntamente com as restrições, é enviada a um novo processo de software que realizará a validação adicional (Figura 8-2).
Estas alterações são invisíveis para o utilizador do sistema. Ele só sentirá mudanças na preocupação que agora terá que ter em relação à normalização de informação.
- Nível de Aplicacional
Este nível diz respeito ao novo componente (o processo adicional de validação) que se passa a descrever. Como se pode ver na Figura 8-2, este processo é composto por vários subcomponentes/funções. O maior e mais complexo foi designado por Validador-CAMILA (devido à linguagem e sistema de prototipagem em que foi desenvolvido - [ABNO97]). Os outros foram baptizados de acordo com a sua funcionalidade: dtd2cam, esis2cam e nsgmls que é o conhecido parser de SGML desenvolvido por James Clark [Cla96d].
O processo é centrado na função Validador-CAMILA, que recebe três tipos de informação provenientes dos outros intervenientes e produz um resultado. O DTD concebido na fase de análise é enviado ao dtd2cam, que traduz a definição dos elementos com as restrições associadas num modelo CAMILA (tipos com invariantes associados), passando este ao Validador-CAMILA. As restrições que são escritas directamente na linguagem CAMILA vão directamente para o Validador-CAMILA.
Do outro lado e já com um autor a editar documentos, quando este quer validar o documento que está a editar, activa a função valida que começa por enviar o documento ao nsgmls; o resultado à saída do nsgmls (o documento no formato ESIS - formato intermédio usado nas aplicações SGML), que normalmente é ignorado a menos das mensagens de erro, é enviado ao processo esis2cam, que vai usá-lo para instanciar a estrutura já definida em CAMILA, traduzindo as instâncias dos elementos no documento em expressões CAMILA (termos dos tipos de dados algébricos).
Assim, o Validador-CAMILA em posse do DTD (traduzido pelo dtd2cam), das restrições e do documento (traduzido pelos nsgmls e esis2cam) pode desencadear a validação semântica, bastando para isso executar as restrições.
Como resultado, o Validador-CAMILA envia ao utilizador um OK ou uma lista de mensagens de erro.
É facilmente perceptível que este processo não é simples e de que várias decisões foram tomadas no curso da sua implementação.
No resto do capítulo, traça-se o percurso de um documento que irá atravessar o sistema. Aproveitam-se vários estados dessa passagem para ilustrar as decisões tomadas na sua implementação e respectivos porquês.
8.4.1. Implementação
O processo, cujo comportamento foi descrito na secção anterior, compreende duas tarefas de tradução.
A primeira é resolvida por um processador, esis2cam, que converte um documento, depois deste ter passado o processo de validação tradicional, em formato ESIS (Secção 5.3) em expressões CAMILA.
Aplicando o nsgmls ao exemplo que se tem vindo a acompanhar, o resultado ESIS seria o seguinte:
(rei
(nome
-D. Dinis
)nome
...
(decreto
A valor CDATA "1300.07.15"
A tipo CDATA "date"
(data
-1300.07.15
)data
(corpo
-A partir do dia de hoje ...
)corpo
)decreto
...
)reiNo passo seguinte, esis2cam irá converter este resultado em termos do modelo abstracto CAMILA gerado por dtd2cam.
A segunda tarefa de tradução (dtd2cam) não é tão simples pois envolve um mapeamento entre um DTD e uma álgebra:
o DTD é traduzido para um modelo na teoria de SETs.
cada elemento é mapeado num tipo, de acordo com um esquema de tradução [RAH95, RAH98].
cada elemento tem uma restrição a ele associada que ficará agora associada ao tipo.
uma restrição é um conjunto de pares: condição - reacção; por omissão tem o valor verdadeiro; a condição e a reacção são escritas de acordo com a sintaxe CAMILA com a utilização de operadores CAMILA (Secção 2.2).
O próximo exemplo demonstra a aplicação deste processo ao caso dos "reis e decretos" que tem vindo a ser seguido.
Exemplo 8-6. Dum DTD para CAMILA
O DTD que se tem vindo a usar é composto pelas seguintes declarações:
<!ELEMENT rei -- (nome, cognome, datan, datam,decreto+)>
<!ELEMENT decreto -- (data, corpo)>
<!ELEMENT (nome,cognome,datan,datam,data)
-- (#PCDATA)>
<!ATTLIST (datan,datam,data)
valor CDATA #IMPLIED
tipo CDATA #FIXED date>
<!ELEMENT corpo -- (#PCDATA)>Aplicando dtd2cam a este DTD obtem-se:
TYPE
rei=nome_ :text
cognome_ :text
datan_ :date
datam_ :date
decreto_l :decreto-seq
decreto=data_ :date
corpo_ :text
ENDTYPE
rei(r)=true;
decreto(d)=true;
...Elementos estruturados são mapeados em tuplos: rei e decreto.
Elementos atómicos sem um tipo associado são automaticamente definidos como sendo text: nome e cognome.
Elementos com um tipo associado são definidos como sendo desse tipo: datan, datam e data.
Elementos com indicadores de ocorrência são definidos como listas.
Por fim, é gerado um invariante para cada elemento. O invariante gerado é uma tautologia podendo e devendo ser reescrito pelo analista conforme as restrições que este quiser impôr.
Termina aqui a travessia do sistema.
Os exemplos práticos obtidos com esta abordagem demonstraram que esta é uma boa solução para a implementação da validação semântica. Não aumenta muito a complexidade do sistema e não altera as aplicações SGML existentes.
No entanto, traz complicações acrescidas para a pessoa que especifica. Esta tem que ter conhecimento da estrutura inerente tendo mesmo que especificar as travessias necessárias.