4.3. Componentes de um Documento SGML
Um documento SGML é composto por três grandes e distintas partes: o Prólogo, o DTD e a Instância.
4.3.1. Prólogo
O prólogo é uma parte formal de cada documento SGML. Especifica, por exemplo, quais os caracteres que podem ser utilizados na escrita dos documentos e dentro destes, quais os que serão utilizados como limites das anotações e, muitas outras características de baixo nível como o limite máximo do tamanho dos identificadores das anotações.
Um prólogo tem as seguintes características:
é, normalmente, comum a todos os documentos SGML num dado ambiente.
pode ou não fazer parte do documento (no caso da sua ausência será usado um por omissão - o definido na norma).
fornece detalhes precisos de como o SGML será aplicado ao documento.
define os caracteres que serão usados para distinguir as anotações do texto (e.g. <, >, />).
define o conjunto de caracteres (ASCII, EBCDIC ou outro) que vai ser utilizado.
Um utilizador não precisa de conhecer a existência do prólogo para criar e manusear documentos SGML. Uma vez que este define aspectos de muito baixo nível, os sistemas SGML trazem alguns prólogos previamente definidos que permitem aos utilizadores abstrairem-se completamente da sua existência.
Exemplo 4-2. Um Prólogo SGML
<!SGML "ISO 8879:1986"
CHARSET
BASESET "ISO 646:1983//CHARSET
International Reference Version (IRV)//ESC 2/5 4/0"
DESCSET 0 9 UNUSED -- os primeiros 10 caracteres
começando em 0
não são utilizados--
9 2 9 -- os próximos, 9 e 10, são
mapeados nos caracteres 9
e 10 da base (BASESET)--
11 2 UNUSED -- o 11 e o 12 não são usados --
13 1 13 -- o 13 é mapeado no 13 --
14 18 UNUSED -- os próximos 18, começando
no 14, não são usados --
32 95 32 -- os próximos 95, começando
no 32, são mapeados
nos caracteres 32-126 do
conjunto base (BASESET) --
127 1 UNUSED -- o carácter 127 não é usado --
CAPACITY PUBLIC "ISO 8879:1986//CAPACITY Reference//EN"
SCOPE DOCUMENT
SYNTAX PUBLIC "ISO 8879:1986//SYNTAX Reference//EN"
FEATURES
MINIMIZE
DATATAG NO
OMITTAG YES
RANK NO
SHORTTAG YES
LINK
SIMPLE NO
IMPLICIT NO
EXPLICIT NO
OTHER
CONCUR NO
SUBDOC NO
FORMAL NO
APPINFO NONE
>No entanto, o prólogo que vem configurado por omissão (ver Exemplo 4-2) está relacionado com as línguas anglo-saxónicas e compreende apenas metade dos caracteres ASCII. Os países mais ocidentais da Europa, nos quais se inclui Portugal, necessitam do ASCII estendido na escrita dos seus textos. Portanto, na instalação de um sistema SGML deve ter-se o cuidado de instalar um prólogo que inclua os caracteres do ISO LATIN1 como o prólogo por omissão, ou em casos mais complicados incluir o Unicode [Unicode].
4.3.2. DTD
A anotação de um elemento é composta por duas marcas, uma anotação de início do elemento e uma anotação de fim. Estas anotações irão descrever as qualidades características do elemento. Uma daquelas características é o identificador genérico, que identifica o tipo do elemento: parágrafo, figura, lista, ... Adicionalmente, um elemento poderá ser qualificado por mais características que lhe são inerentes; estas recebem a designação de atributos.
As anotações descrevem a estrutura de um documento. Indicam quais os elementos que ocorrem no documento e em que ordem. Esta estrutura tem de ser válida de acordo com o conjunto de declarações no DTD que definem todas as estruturas permitidas num determinado tipo de documento.
Para introduzir este conceito de DTD, recorre-se ao exemplo seguinte. Nesse exemplo, todas as linhas começadas por "<!--" são comentários e destinam-se a esclarecer o objectivo geral do tipo de documento e os de cada elemento em particular.
Exemplo 4-3. DTD para uma carta
<!-- Este DTD define a estrutura de docs do tipo CARTA --> <!DOCTYPE CARTA [ <!-- Uma carta é uma sequência de elementos: --> <!-- um destinatário, um texto de abertura, um corpo e --> <!-- um texto de fecho. --> <!ELEMENT CARTA - - (DEST, ABERTURA, CORPO, FECHO)> <!-- O destinatário é texto. --> <!ELEMENT DEST - - (#PCDATA)> <!-- A abertura é texto. --> <!ELEMENT ABERTURA - - (#PCDATA)> <!-- O corpo é composto por um ou mais parágrafos. --> <!ELEMENT CORPO - - (PARA)+> <!-- Um parágrafo é composto por texto podendo ter uma ou --> <!-- mais listas intercaladas. --> <!ELEMENT PARA - - (#PCDATA | LISTA)+> <!-- Uma lista é uma sequência de um ou mais items. --> <!ELEMENT LISTA - - (LITEM)+> <!-- Um item é texto. --> <!ELEMENT LITEM - - (#PCDATA)> <!-- O fecho é texto. --> <!ELEMENT FECHO - - (#PCDATA)>
Este DTD é muito simples, contém apenas declarações de elementos. Mesmo assim, permite escrever cartas estruturadas e anotadas e ainda, fazer a validação estrutural desses documentos.Contudo, está ainda um pouco distante de um DTD real que contém normalmente maior riqueza informativa.
Formalmente, pode-se dizer que um DTD é composto por um conjunto de declarações. Existem quatro tipos de declarações: elementos, atributos, entidades e instruções de processamento.
4.3.2.1. Elementos
Um elemento é definido no DTD numa declaração do tipo ELEMENT, que obedece à seguinte estrutura:
<!ELEMENT identificador - - (exp-conteúdo) excepção>
- identificador
identificador do elemento
- expressão de conteúdo
definição do conteúdo do elemento expressa numa linguagem de expressões regulares que obedece a uma álgebra [Omn98c]. A expressão regular que define o conteúdo do elemento especifica que subelementos podem aparecer, em que ordem e em que número.
- excepção
a excepção é opcional e permite modificar a definição do conteúdo do elemento, permitindo elementos opcionais não mencionados na expressão de conteúdo e/ou excluindo outros elementos opcionais permitidos pela expressão de conteúdo.
4.3.2.1.1. Álgebra do Conteúdo
Nas expressões regulares que podem aparecer a definir o conteúdo dos elementos há dois tipos de operadores: operadores de sequência ou conexão e operadores de ocorrência.
4.3.2.1.1.1. Operadores de Conexão
São normalmente colocados entre dois subelementos e especificam a ordem em que podem ocorrer:
- ,
Exemplo: (a, b) -- significa que este elemento tem que ser composto por um elemento a e um elemento b, e que a deve preceder b.
Do exemplo anterior:
<!ELEMENT CARTA - - (DEST, ABERTURA, CORPO, FECHO)>
uma carta é obrigatoriamente constituída por um destinatário, uma abertura, um corpo e um fecho, nesta ordem.- |
Exemplo: (a | b) -- significa que o elemento corrente é composto por um elemento a ou um elemento b.
- &
Exemplo: (a & b) -- significa que o elemento corrente é composto por um elemento a e por um elemento b sem ordens de precedência, i.e., desde que os dois estejam presentes, a ordem não importa.
Se na declaração anterior de carta se substituíssem os operadores:
<!ELEMENT CARTA - - (DEST& ABERTURA& CORPO& FECHO)>
a constituição de um documento carta seria a mesma, a ordem dos elementos é poderia ser qualquer, por exemplo, uma carta poderia iniciar-se com o fecho.Na prática, este operador deve ser evitado porque, como se verá mais à frente, apesar de nos facilitar a especificação do tipo de alguns documentos mais complicados, levanta alguns problemas de processamento e portabilidade.
4.3.2.1.1.2. Operadores de Ocorrência
São aplicados individualmente a um elemento ou a uma estrutura já especificada.
- ? (0 ou 1 vez)
Exemplo: (a?,b) -- o elemento que tem este conteúdo tem que ser constituído opcionalmente por um elemento a seguido de um elemento b.
- * (0 ou mais vezes)
Exemplo: (a*,b) -- o elemento que tem este conteúdo tem que ser constituído por zero ou mais elementos a seguidos de um elemento b.
- + (1 ou mais vezes)
Exemplo: (a+,b) -- o elemento que tem este conteúdo tem que ser constituído por um ou mais elementos a seguidos de um elemento b.
Resumindo, a álgebra do conteúdo define uma linguagem composta por strings de caracteres e elementos do documento. Representa-se o conjunto de caracteres por &Sgr;. As expressões que definem o conteúdo dos vários elementos num DTD são muito semelhantes a expressões regulares sobre um alfabeto V, que é composto pelos identificadores de tipo dos elementos do DTD e #PCDATA. Os membros de V serão referenciados como símbolos. A linguagem L(E) definida por uma expressão de conteúdo E define-se indutivamente como se segue (&egr; representa a string vazia):
L(#PCDATA) = {v1...vn|v1...vn ∈ &Sgr;, n ≥ 0}
L(a) = {a} para a ∈ V - {#PCDATA}
L(F|G) = L(F) U L(G)
L(F,G) = {vw | v ∈ L(F), w ∈ L(G)}
L(F?) = L(F) U {&egr;}
L(F*) = {v1...vn | v1, ..., vn ∈ L(F), n ≥ 0}
L(F+) = {v1...vn | v1, ..., vn ∈ L(F), n ≥ 1}
L(F1&...&Fn) = {v1...vn | vi ∈ L(F&phgr;(i)), i=1, ..., n e
&phgr; é uma permutação de {1, ..., n}Num capítulo final, onde se discutirá a implementação de um sistema baseado em SGML volta-se a abordar esta álgebra de conteúdos referindo alguns problemas de concepção da norma que fazem com que a implementação de um parser SGML seja extremamente difícil e trabalhosa.
4.3.2.1.2. Excepções
Como já foi referido, as excepções permitem alterar a expressão de conteúdo de um elemento, forçando a inclusão ou a exclusão de certos elementos. Trata-se de mais uma característica relacionada com as limitações da tecnologia informática da altura (1986): editores de texto simples, ausência de apoio contextual. As excepções surgiram para abreviar a escrita dos DTDs, no entanto, a sua presença num DTD torna o parsing deste muito complicado.
Os dois tipos de excepção demonstram-se nos exemplos seguintes.
O primeiro descreve a inclusão.
Exemplo 4-4. Inclusão
No desenvolvimento de um DTD para o tipo de documentos MEMO podía-se querer tomar a decisão de ter um elemento NOTA-RODAPE "pendurado" em qualquer um dos subelementos de MEMO. Em vez de adicionar o elemento NOTA-RODAPE às expressões de conteúdo de todos os elementos (o que pode não ser simples para expressões complexas), pode-se abreviar esta tarefa ligando o elemento NOTA-RODAPE ao elemento raiz MEMO através de uma inclusão.
A sintaxe de uma inclusão é a seguinte:
<!ELEMENT nome minimização (exp-conteúdo) +(inclusão)>
Assim, a situação anterior seria especificada da seguinte maneira:
<!ELEMENT MEMO - - ((PARA & DE),CORPO,FECHO?) +(NOTA-RODAPE)>
Por razões de eficiência e dificuldade de processamento que serão discutidas mais à frente, as inclusões devem ser utilizadas com algum cuidado e, preferencialmente, para elementos que não fazem parte do conteúdo lógico no ponto em que ocorrem. Por exemplo: palavras-chave, entradas de um índice remissivo, entradas do índice geral, figuras, tabelas, ...
O segundo exemplo descreve a exclusão.
Exemplo 4-5. Exclusão
Pode surgir uma situação em que um elemento deva ser excluído do conteúdo de um dado elemento. Um exemplo disso é o controlo do mecanismo de inclusão no sentido de evitar recursividades indesejáveis. No exemplo anterior (Exemplo 4-4), a NOTA-RODAPE não deverá ocorrer dentro do seu próprio conteúdo. Isto pode ser conseguido através de uma exclusão.
A sintaxe genérica para as exclusões é a seguinte:
<!ELEMENT nome minimização (exp-conteúdo) -(exclusão)>
Na continuação do exemplo anterior, introduziram-se as seguintes declarações no DTD:
<!ELEMENT NOTA-RODAPE - - (PARAGRAFO+) -(NOTA-RODAPE)> <!ELEMENT PARAGRAFO - - (TEXTO | NOTA-RODAPE)+> <!ELEMENT TEXTO - - (#PCDATA)>
Um elemento só pode ser excluído se for opcional, se for repetitivo ou, se ocorrer numa alternativa. A exclusão de um elemento obrigatório dá origem a uma situação de erro.
Normalmente, as exclusões servem para limitar a recursividade das inclusões. Para evitar que um documento se torne não-estruturado, as exclusões deverão ser usadas, sempre que possível, no nível mais baixo da árvore documental.
4.3.2.2. Atributos
Um elemento pode ter um ou mais atributos que, por sua vez, podem ser opcionais ou obrigatórios. Os atributos visam qualificar o elemento a que estão associados. A especificação de atributos num DTD pode ser comparada à especificação de parâmetros num programa escrito numa linguagem de programação, ou pode-se ainda traçar um paralelo com a língua portuguesa: os elementos seriam substantivos e, os atributos, os adjectivos. Assim:
Isto é uma casa == <CASA>
Isto é uma casa verde == <CASA COR='verde'>
Os atributos devem aparecer sempre na anotação que marca o início do elemento, uma vez que vão qualificar o conteúdo que se segue. Não há limite para o número de atributos que podem estar associados a um elemento.
Especificou-se atrás um DTD para o tipo de documento carta. Suponha-se que agora se pretendia classificar cada uma das cartas escritas de acordo com aquele DTD como pessoais ou públicas. Isso pode ser feito associando ao elemento carta um atributo tipo com a possibilidade de ter os valores "pessoal" ou "pública":
<!ATTLIST CARTA TIPO (pessoal | pública) pública>
Adicionalmente, os valores dos atributos podem ser mais do que simples strings, podem ter uma semântica específica. Por exemplo, um atributo pode ser declarado de modo a que o valor que a ele seja associado seja único. Isto é o que se pode chamar de identificador chave e que pode ser usado para referenciar e localizar um elemento numa instância de um documento. Este identificador chave pode ser usado por outros elementos para o referenciarem num contexto hipertextual.
A declaração de atributos em SGML tem a seguinte forma:
<!ATTLIST elem-id
att1-id att1-tipo att1-valor-omissao
...
attn-id attn-tipo attn-valor-omissao
>Onde:
- elem-id
É o identificador do elemento ao qual os atributos ficarão associados.
- atti-id
É o identificador do atributo i.
- atti-tipo
É o tipo do atributo i.
- atti-valor-omissao
É o valor por omissão do atributo i.
No quadro seguinte, descrevem-se os tipos de atributo mais relevantes e em uso.
Tabela 4-1. Tipos de Atributo
| Tipo | Descrição |
|---|---|
| CDATA | o valor do atributo será uma string (é o tipo de atributo mais usado) |
| ENTITY | o valor do atributo deverá ser o identificador de uma entidade declarada no DTD |
| ID | o valor do atributo deverá ser um identificador único em todo o documento |
| IDREF | o valor do atributo deverá ser um identificador pertencente a um atributo do tipo ID de outro elemento (implementação das referências) |
| NOTATION | o valor do atributo deverá ser um identificador de uma notação declarada no DTD |
| NUMBER | o valor do atributo é numérico |
Por sua vez, o quadro seguinte descreve os valores por omissão dos atributos:
Tabela 4-2. Valores por omissão
| #IMPLIED | o valor poderá não ser instanciado, o atributo é opcional. |
| #REQUIRED | o utilizador terá obrigatoriamente que instanciar o atributo, este é obrigatório |
| #FIXED | o valor do atributo tem que aparecer a seguir à palavra-chave (ver Secção 7.1, Exemplo 7-3) significando que se o atributo for instanciado terá que ser com um valor igual ao declarado, caso não seja instanciado o sistema assumirá esse valor. |
| #CURRENT | o valor do atributo é herdado da última instância do mesmo elemento onde o valor do atributo foi instanciado (segue-se a ordem ascendente na árvore de elementos) |
| #CONREF | o valor é usado para referências externas (cada vez menos utilizado, não irá ser considerado nas regras que se seguem) |
| valor de um tipo enumerado | um dos valores pertencentes ao tipo enumerado definido para esse atributo. |
Para terminar a descrição dos atributos, apresenta-se um exemplo comum a quase todas as publicações, as referências bibliográficas.
Exemplo 4-6. Atributos - tipos e valores
Numa lista de items bibliográficos:
<BIB.LISTA> <BIB.ITEM IDENT='Saramago'> <AUTOR>José Saramago</AUTOR> <TITULO>Jangada de Pedra</TITULO> ...
Ao item bibliográfico (<BIB.ITEM) atribui-se um identificador chave ao seu atributo IDENT, que pode agora ser usado noutros sítios para referenciar este item.
As referências aos items bibliográficos podem ser feitas usando um elemento específico para o efeito, por exemplo, BIB.REF, que terá um atributo, por exemplo, REFIDENT, que irá ter um valor previamente atribuído a um atributo IDENT de um item bibliográfico:
O escritor de muitas obras, das quais se destaca "Jangada de Pedra" <BIB.REF REFID='Saramago'> ...
As respectivas declarações em SGML seriam:
<!ATTLIST BIB.ITEM IDENT ID #IMPLIED> <!ATTLIST BIB.REF REFID IDREF #REQUIRED>
4.3.2.3. Entidades
Um documento SGML pode estar espalhado por vários ficheiros do sistema. Facilita-se desta maneira a reutilização de subcomponentes, dentro do próprio documento ou noutros documentos e permite-se que informação noutro formato seja inserida no documento. No resto desta secção, vai-se descrever o mecanismo do SGML que suporta estas facilidades.
4.3.2.3.1. Conceitos
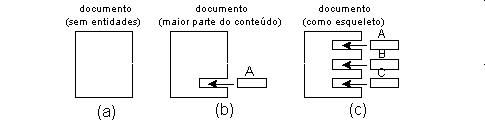
O SGML tem um mecanismo que permite isolar fisicamente e armazenar separadamente qualquer parte de um documento. Por exemplo, cada capítulo de um livro pode ser gravado em ficheiros distintos, ou, as figuras podem estar guardadas separadamente e podem ser inseridas num dado ponto do documento. Cada uma destas unidades de informação é designada por entidade e tem um identificador único associado pelo qual é referenciada. A única excepção é a entidade correspondente ao documento principal que não precisa do identificador pois é normalmente referenciada pelo nome do ficheiro que a contém. Nos casos mais simples, esta será a única entidade relacionada com o documento (o documento SGML está contido num ficheiro - Figura 4-3 a). Noutros casos, o ficheiro principal terá a maior parte do conteúdo do documento, contendo referências a outras entidades que identificam os ficheiros com o conteúdo que preencherá alguns intervalos (Figura 4-3 b). No outro extremo, a entidade/ficheiro principal não é mais do que um esqueleto, usado para posicionar o conteúdo de outras entidades (Figura 4-3 c).
Uma entidade é definida numa declaração própria que normalmente aparece no início do DTD. Nesta declaração é atribuído um nome à entidade e é-lhe associado um conteúdo ou uma referência para um ficheiro externo onde está esse conteúdo.
As entidades são usadas por referência, i. e., o autor coloca uma referência no texto que identifica univocamente uma entidade. Não há limite para o número de referências a uma mesma entidade num documento. Mais tarde, quando o documento for processado as referências são substituídas pelos respectivos conteúdos.
No texto de uma entidade poderá haver referências a outras entidades. No entanto, não são permitidas referências cíclicas.
Deve-se ter algum cuidado na utilização de entidades e ter alguma atenção na limitação da sua utilização. O seu uso abusivo aumenta a complexidade do tratamento do documento. Há, no entanto, várias situações em que a utilização de entidades deve ser considerada:
quando a mesma informação é utilizada algumas vezes no documento; a duplicação é sempre susceptível de erros e tem custos temporais.
quando a informação tem representações diferentes em sistemas incompatíveis.
quando informação diz respeito a um grande documento que deve ser separado em unidades mais pequenas de modo a facilitar a sua manutenção.
quando a informação é composta por dados num formato diferente do SGML.
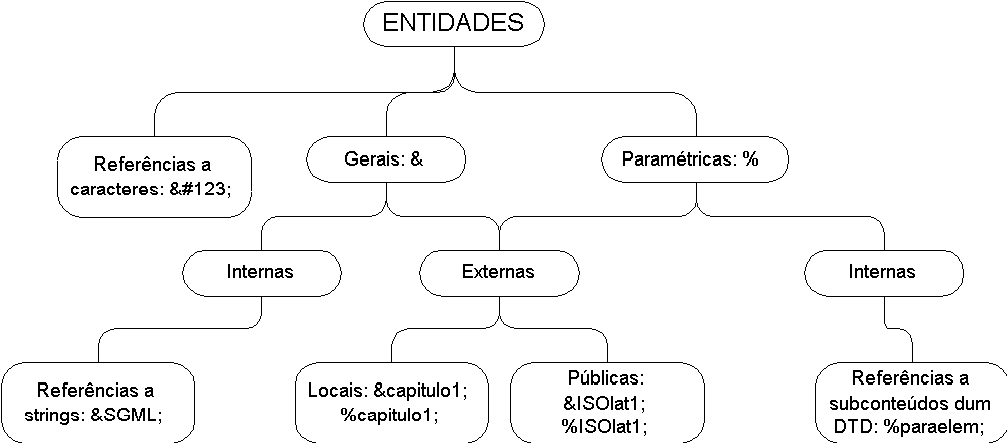
Dos princípios acima enunciados infere-se que é necessário mais de um tipo de entidade de modo a poder-se tratar informação SGML e informação que não é SGML, unidades de grandes dimensões e outras de pequenas dimensões:
- entidades gerais
são usadas como um mecanismo de abreviaturas para strings grandes de texto que se irão repetir ao longo de um texto (situação análoga à definição de constantes, ou macros, nas linguagens de programação).
- entidades carácter
representam a maneira de codificar caracteres especiais: caracteres acentuados, letras de outros alfabetos e alguns símbolos matemáticos.
- entidades externas
servem para referenciar ficheiros externos, de modo a ser possível incluí-los nos pontos adequados.
- entidades paramétricas
são usadas como variáveis na escrita de DTDs, para abreviar a sua escrita e tornar as expressões regulares de conteúdo mais simples.
As referências a entidades gerais devem ser colocadas no texto onde se pretender que aquelas sejam expandidas.
Figura 4-4. Os vários tipos de entidades
4.3.2.3.2. Entidades Gerais
Tal como os elementos e os atributos as entidades são definidas no DTD numa declaração própria.
Exemplo 4-7. Declaração de uma entidade geral
Sintaxe da declaração: <!ENTITY identificador "conteúdo" >
Exemplo:
<!ENTITY SGML "Standard Generalized Markup Language">
Depois, podem ser utilizadas no texto com uma sintaxe específica.
Exemplo 4-8. Referência a uma entidade geral
Sintaxe da referência: & identificador ;
Exemplo:
"A migração para uma tecnologia baseada em &SGML; tem custos que ...
Na escrita desta tese foram utilizadas entidades gerais de uma forma peculiar para resolver um problema prático e específico. O DTD usado traz nele incluídas algumas bibliotecas de entidades especiais que mapeiam caracteres matemáticos, gregos, etc. Para a escrita de algumas definições matemáticas estava-se a usar uma biblioteca de letras caligráficas, "ISOmscr.gml". O problema é que nenhum dos "back-ends" utilizados, RTF e HTML, mapeia aqueles caracteres na fonte apropriada e até um dia isso acontecer foi preciso arranjar uma solução de compromisso: mapeou-se cada um dos caracteres num elemento de realce como se pode ver no seguinte exemplo.
Exemplo 4-9. Entidades gerais utilizadas na escrita da tese
<!ENTITY ascr "<EMPHASIS>a</EMPHASIS>">
<!ENTITY bscr "<EMPHASIS>b</EMPHASIS>">
<!ENTITY dscr "<EMPHASIS>d</EMPHASIS>">Assim, quando no texto se usa uma daquelas entidades, por exemplo 𝒶, sempre que o documento é processado a entidade é substituída pelo elemento EMPHASIS com conteúdo igual à letra correspondente. Mais tarde, se os caracteres correspondentes a estas entidades vierem a ter o suporte desejado por parte dos "backends", aquelas poderão vir a ser retiradas ou colocadas em comentário.
4.3.2.3.3. Entidades carácter
O conjunto de caracteres definido no prólogo de um documento SGML pode ser muito mais lato do que os caracteres que o teclado disponibiliza. As entidades carácter vêm possibilitar a referência de qualquer carácter definido no prólogo.
O nome destas entidades é o número decimal correspondente ao carácter que se quer referenciar. Por exemplo, no caso dos caracteres ASCII a entidade de nome 65 corresponde ao carácter A.
Sintaxe da declaração: A sua declaração está intrínseca na declaração dos caracteres no prólogo.
Sintaxe da referência: &# identificador ;
Exemplo 4-10. Referência a uma entidade carácter
... a flecha tinha-lhe trespassado o cora„ão.
4.3.2.3.4. Entidades externas
Quando um documento cresce e atinge dimensões consideráveis, a sua edição pode tornar-se penosa e difícil. Numa situação destas, a solução é dividir o documento em unidades mais pequenas, havendo um documento principal a integrar aquelas unidades. Esta tese, por exemplo, encontra-se repartida em vários ficheiros SGML. A política seguida foi a separação por capítulos.
Esta filosofia é implementada em SGML através de entidades externas. Uma entidade externa corresponde a uma das partições do documento original. No documento principal, colocam-se referências às entidades externas no local onde deveriam ser inseridos os respectivos ficheiros SGML.
Exemplo 4-11. Declaração de uma entidade externa
Sintaxe da declaração: <!ENTITY identificador [PUBLIC identificador-público] [SYSTEM path]
Os blocos entre "[" e "]" são opcionais mas um deles deverá estar presente. Os dois blocos dizem respeito aos dois métodos possíveis de endereçamento dos ficheiros externos: indirectamente através de identificador público ou, directamente através do nome e local do ficheiro no sistema.
O método indirecto surge para facilitar a gestão dos ficheiros dentro do sistema. Pressupõe a existência de um ficheiro com o nome catalog, que faz o emparelhamento entre identificadores públicos e nomes de ficheiros. Um identificador público é uma string que obedece a um conjunto de requisitos estipulados numa norma [Spy97].
Exemplo:
<!ENTITY capitulo1 SYSTEM "a:\cap1.sgm"> <!ENTITY capitulo2 PUBLIC " -//jcr//Capitulo 2 da tese//PT"> <!ENTITY fig1 PUBLIC " -//jcr//Figura 1//PT" "a:\fig1.gif">
Aqui estão as três hipóteses para a declaração de uma entidade externa: identificador do sistema, identificador público e identificador público mais identificador de sistema (este último terá precedência na maior parte das situações).
Como foi referido, a utilização de identificadores públicos é um mecanismo indirecto para o endereçamento de ficheiros que relega para um catálogo a missão de emparelhar os identificadores com os ficheiros do sistema. Apresenta-se a seguir um exemplo de um pequeno catálogo que deveria acompanhar o exemplo anterior.
Exemplo 4-12. Identificadores públicos e o Catálogo
O catálogo referente às declarações anteriores teria o seguinte aspecto:
PUBLIC " -//jcr//Capitulo 2 da tese//PT" "a:\cap2.sgm" PUBLIC " -//jcr//Figura 1//PT" "a:\fig1.gif" ...
A utilidade mais óbvia deste mecanismo é a movimentação de ficheiros. Se se pretender mover os ficheiros no sistema para uma directoria diferente só será necessário alterar as respectivas paths no catálogo, caso contrário haveria que percorrer todos os documentos no sistema e fazer a alteração em todos os que incluíssem as entidades em causa (lembrar que as entidades são reutilizáveis em vários documentos).
As entidades externas são referenciadas como todas as outras que vistas até agora.
Exemplo 4-13. Referência a uma entidade externa
Sintaxe da referência: & identificador ;
Exemplo: ... &capitulo1;...
A seguir apresenta-se um exemplo que mostra como as entidades externas foram utilizadas para modularizar a escrita desta dissertação seguindo o esquema apresentado na Figura 4-3.
Exemplo 4-14. Entidades externas e escrita modular de documentos
<!DOCTYPE BOOK PUBLIC "-//Davenport//DTD DocBook V3.0//EN"
[
<!ENTITY capítulo1 SYSTEM "chap-doc-est.sgm" --Documentação Estruturada-->
<!ENTITY capítulo2 SYSTEM "chap-int.sgm" --Introdução-->
<!ENTITY capítulo3 SYSTEM "chap-sgml.sgm" --SGML-->
<!ENTITY prefacio SYSTEM "prefacio.sgm" --teste de módulos-->
]>
<BOOK LANG="pt">
<BOOKINFO>
<BOOKBIBLIO>
<TITLE>Anotação Estrutural de Documentos
...
&capítulo1;
&capítulo2;
&capítulo3;
...As entidades externas podem ainda ser usadas para incluir num documento objectos externos como imagens, audio ou video.
4.3.2.3.5. Entidades paramétricas
Uma entidade paramétrica é normalmente utilizada na construção do DTD para abreviar a escrita de partes constantes. A sua declaração é semelhante às outras apenas leva o sinal de percentagem, %, depois da palavra chave ENTITY.
Exemplo 4-15. Entidades paramétricas
<!ENTITY % listas "ldescritiva |
lenumerada |
lnormal">
...
<!ELEMENT para - - (#PCDATA | %listas; | ...)>
<!ELEMENT ldescritiva - - (...)>
...Pode ser definida uma entidade geral com o mesmo nome desde que se omita o sinal de percentagem.
Exemplo 4-16. Entidades com o mesmo nome
<!ENTITY % UmaEntidade "(paragrafo | lista)"> <!ENTITY UmaEntidade "Isto é uma entidade.">
Para que seja possível distinguir as referências a entidades paramétricas das referências a entidades gerais (uma vez que podem ter o mesmo nome), substitui-se o carácter limitador de início, "&", pelo carácter "%".
4.3.2.4. Instruções de Processamento
Uma instrução de processamento contém informação específica para uma aplicação que irá processar o documento SGML. Ao contrário das outras declarações, uma instrução de processamento não tem regras ou estrutura a seguir, tudo é válido dentro dos limitadores que são respectivamente "<?" e "?>".
O conteúdo de uma instrução de processamento começa normalmente por uma palavra chave significativa para uma das aplicações que irá processar o documento a seguir. Segue-se um espaço que separa a palavra chave do código da instrução de processamento. É assumido que a sintaxe faz sentido para alguma das aplicações que a seguir irá processar o documento. Caso contrário, o seu conteúdo será simplesmente ignorado.
Exemplo 4-17. Instrução de Processamento
... <paragrafo>Seria bom se a página terminasse aqui... <?TeX \newpage?> <?HTML <P><HR>?> </paragrafo> ...
Pretende-se que, quer na geração para LaTeX quer na geração para HTML fosse introduzido um separador mais forte no meio do parágrafo. Assim, colocaram-se duas instruções de processamento uma para TeX e outra para HTML. É claro que esta não é a maneira de fazer as coisas respeitando a filosofia do SGML, pois está-se a adicionar informação específica dependente de plataformas. A maneira correcta de fazer o mesmo seria inserir um elemento vazio que marcaria a quebra de página. De qualquer forma haveria uma violação parcial da filosofia do SGML pois estar-se-ia a introduzir um elemento com conotações semânticas de forma e não de estrutura.
4.3.3. Instância
A instância é o documento propriamente dito e que é composto por:
texto - conteúdos.
anotações - que delimitam os elementos estruturais.
uma referência ao DTD (caso este não esteja presente no documento).
Usa-se o termo instância porque se trata de uma realização concreta de uma classe de documentos que tem a estrutura definida por um DTD.
A título de exemplo apresenta-se uma instância de um documento do tipo CARTA cujo DTD foi definido no início deste capítulo (Exemplo 4-3).
Exemplo 4-18. Instância de CARTA
<!DOCTYPE CARTA SYSTEM "carta.dtd">
<CARTA>
<DEST>Meus amigos</DEST>
<ABERTURA>Caríssimos,</ABERTURA>
<CORPO>
<PARA>Na impossibilidade de poder contactá-los a todos de forma mais personalizada,
envio esta carta electrónica com os meus votos de: UM BOM NATAL e BOAS ENTRADAS
num novo ano que muito promete.</PARA>
</CORPO>
<FECHO>Até ao novo ano</FECHO>
</CARTA>Termina aqui a descrição da norma SGML. No próximo capítulo, descreve-se o ciclo de vida de um documento SGML: que fases, que ferramentas, que outras normas interagem com o SGML e por fim, como obter um produto final de toda esta tecnologia. Não podia deixar de ser feita aqui uma referência ao arquivo universal de SGML, onde o utilizador poderá encontrar tudo o que desejar desde bibliografia até software, agora mantido pela organização não governamental OASIS que responde no endereço internet: http://www.oasis-open.org/cover