5.5. Armazenamento
Quem trabalha com documentação estruturada tem por objectivo, tirar partido dessa estrutura para outros fins como: extrair partes; poder realizar procuras inteligentes sobre os documentos; criar índices; extrair partes para construir novos documentos por composição; etc. Para isso é necessário armazenar os documentos num ambiente que permita, posteriormente, realizar aquelas operações sobre eles.
Hoje em dia, é banal a associação das bases de dados com o termo armazenar. No entanto, neste contexto, a solução não é tão simples, há que ter em conta a estrutura da informação e a eficiência do sistema de suporte que se irá utilizar.
Actualmente, pode-se dividir o leque de soluções de armazenamento de documentos SGML em três:
Armazenar os documentos no sistema de ficheiros do próprio sistema operativo do computador - não é uma solução tão inocente quanto aparenta! Os documentos têm a estrutura visível através das anotações e, se o sistema possuir um conjunto de ferramentas SGML batch que possa ser utilizado para a implementação das procuras e outras operações pretendidas, o problema fica resolvido (com alguma redundância e confusão a nível de ficheiros, uma vez que DTDs, documentos, entidades e ferramentas de software convivem todos no mesmo espaço).
Armazenar os documentos numa base de dados relacional - parece uma solução óbvia, mas não é. À primeira vista, pode-se ser levado a pensar que basta dividir um documento estruturado nos seus componentes e associar cada um destes a um campo da base de dados. Esta conversão traria perdas irrecuperáveis uma vez que o texto tem uma ordem linear inerente à sua essência e não há qualquer relação de ordem entre os campos de uma tabela de uma base de dados relacional. Assim, se se tentásse armazenar um documento estruturado numa base de dados relacional distribuindo os seus componentes pelos campos de uma ou várias tabelas estar-se-ia a destruir a ordem linear do texto perdendo a capacidade de mais tarde poder voltar a reconstruir o texto original.
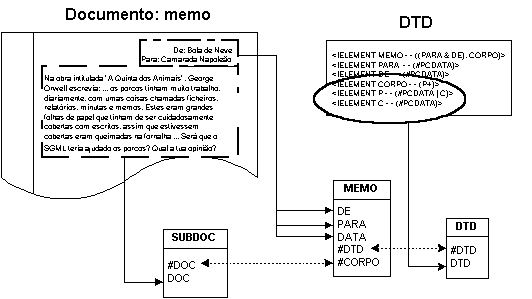
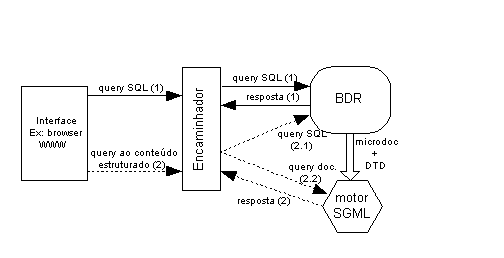
No entanto, devido aos baixos custos que uma solução baseada no modelo relacional representa, houve várias tentativas nesta área. A mais divulgada, utilizada e até usada como imagem de marca foi a proposta e implementada pela Omnimark [Omn98], designada por Micro-Document Architecture - MDA. Esta solução parte de um princípio muito simples: analisa-se a estrutura de um documento e determina-se quais os elementos e subelementos que podem ser separados (que não necessitam da ordem linear do texto), esses elementos são armazenados cada um num campo de uma tabela; depois desta operação resta algum ou alguns subdocumentos para os quais a ordem linear dos seus elementos é importante; estes, são armazenados cada um no seu campo memo que ficará associado a um mini-DTD também armazenado noutra tabela. Desta maneira, os campos de informação que foram separados podem ser utilizados em queries normais da base de dados, os outros podem ser geridos como blocos mas se o pretendido for algo mais inteligente como queries ao seu conteúdo estruturado haverá que envolver um motor de processamento de SGML externo, que faça uso, não só desse campo memo, mas também do mini-DTD a ele associado.
Na Figura 5-19 apresenta-se uma possível solução para estruturar uma base de dados relacional para documentos do tipo MEMO. Por outro lado, na Figura 5-20, pode-se ver a estrutura funcional que teria de ser montada para que o sistema respondesse a queries sobre o conteúdo estruturado dos documentos.
Armazenar os documentos numa base de dados orientada a objectos - solução cara mas eficaz. O modelo hierárquico de objectos modela directamente qualquer árvore documental portanto nada mais lógico do que utilizar este modelo para armazenar os documentos estruturados. Foi o que pensaram vários construtores de software que desenvolveram vários produtos equivalentes para armazenamento e gestão de documentos estruturados [DuC98], dos quais se destacam: o Astoria da Chrystal, o Poet da Poet e o Infomanager da Texcel. Deles só se pode dar uma opinião das demonstrações disponíveis, pois o custo das licenças é extremamente elevado e, quando contactados sobre a hipótese de um acordo com a Educação/Universidade, a sua receptividade foi nula.
Há, no entanto, outros produtos, como o Object Store, que não tendo sido desenvolvidos a pensar no SGML têm sido usados para esse fim, principalmente em projectos de bibliotecas digitais, como a de Alicante - Espanha - "Biblioteca Digital Miguel Cervantes" [DLMC].
De qualquer maneira, a problemática do armazenamento é sempre o último ponto a ser considerado num projecto. O sistema de ficheiros é um recurso utilizado até ao limite. A decisão de aquisição de um sistema de armazenamento é sempre complicada face aos custos envolvidos.
Com este capítulo, encerra-se esta panorâmica geral do que é o mundo dos documentos SGML, como funciona, como é composto, que interacções existem, quais os passos na implementação de um sistema destes.
Nos próximos capítulos entra-se na parte inovadora da tese: que lacunas foram detectadas nesta filosofia de trabalho; que soluções o autor propõe para colmatar aquelas deficiências.