| David Filipe Oliveira Costa | Ricardo Miguel Carvalho Ferreira |
| dfoc@hotmail.com | ricardo_miguel_ferreira@hotmail.com |
| 28873 | 15889 |
No Arquivo Distrital de Braga encontram-se inúmeras obras de grande valor, cuja publicação se realizou via técnicas meramente tipográficas. A inexistência de suporte electrónico destas obras, levou a que aquela entidade e a Universidade do Minho criassem um conjunto de sinergias visando a sua modernização, via processos de informatização.
Este relatório é sobre o processo de publicação electrónica de uma parte dessas obras, o "Inventário dos Livros da Misericórdia".
O Inventário dos Livros da Misericórdia é um documento que, do ponto de vista estrutural, se apresenta heterogéneo e pouco rígido, pelo que a definição da gramática que o rege e o seu processamento merecem atenção e tratamento especiais.
O poder do suporte electrónico estruturado deste documento reside não apenas na capacidade de expeditamente se reproduzirem versões apropriadas tanto para a impressão em papel como para a sua disponibilização na Web, mas também na possibilidade de sobre ele se efectuarem pesquisas contextuais, segundo um determinado conjunto de critérios, como se de uma base de dados convencional se tratasse.
Disponibilizando ao mundo, e à distância de um clique, informação anteriormente menos acessível.
Este projecto foi desenvolvido no âmbito da cadeira de Processamento Estruturado de Documentos do 5º Ano da Licenciatura em Matemática e Ciências da Computação.
Prentende-se com este trabalho converter um documento, do Arquivo Distrital de Braga, para formato digital. O documento que nos foi incumbido de converter é o "Inventário dos livros da Misericórdia desta cidade de Braga existentes no Arquivo Distrital da mesma cidade".Este processo constou naturalmente várias etapas:
O projecto foi realizado, como foi dito, de forma faseada cada fase sujeita a problemas e implicações diferentes, cada uma requerendo abordagens teóricas e práticas diversas.
A simples digitalização de documentos não traz melhorias significativas ao documento, nem traz grandes vantagens em relação à versão manuscrita para os utilizadores. É necessário levar a tarefa mais longe e aproveitar para enriquecer o documento com informação que melhore a pesquisa e estrutura do mesmo. É aqui que entra o XML, que como linguagem de anotação que é, permite enriquecer o documento com informação extra que irá facilitar a geração de índices, a pesquisa e outras vistas do mesmo documento, potenciando assim a consulta do mesmo.
A primeira fase do projecto constou da análise atenta e cuidada do documento original para a construção de um DTD que fosse capaz de suportar e traduzir toda a sua informação, assim como as funcionalidades do formato digital que pretendemos obter.
É de referir também que usamos como ferreamenta de trabalho principal, não um simples editor de texto, mas sim uma ferramenta bem mais poderosa e específica para o efeito: o XML Spy v 4.01, com os procesadores XML e XSL que acompanham a distribuição. Apenas na fase final do trabalho, recorremos ao processador de James Clark, o XT.
A análise do documento original permitiu identificar a constituição do documento, todos os seus elementos, a sua constituição e relacionamento entre as diversas partes. Identificamos partes do documento que podiam ser retiradas do documento quando em formato XML, pois essas podem ser geradas automaticamente.
Tendo em conta tudo isto, elaboramos o DTD, documento.dtd, para o documento.
Depois de estudada e identificada a estrutura do documento, passamos à digitalização do mesmo, para tal fizemos o scanning das páginas do documento original e por intermédio duma aplicação de OCR geramos a primeira versão digital do documento, esta em formato RTF.
Mas essa versão no entanto era muito pouco útil já que a sua formatação era deficiente e não trazia nada de novo ao utilizador, pelo que passamos à fase seguinte.
A primeira fase de anotação do documento foi conseguida com uma script denominada rtf2xml cuja função é transformar um ficheiro em formato RTF num de formato XML com a mesma informação. O documento obtido apesar de estar no formato XML era no entanto muito pobre a nível de anotações úteis para o que pretendiamos, pois as que continha tinham derivado da formatação RTF.
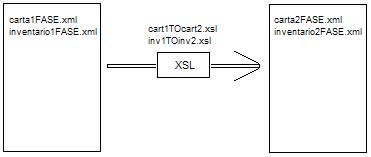
Seguidamente, dividimos ainda o documento em duas partes: a carta inicial (carta1FASE.xml) e o inventário propriamente dito (inventario1FASE.xml).
Entenda-se por documento XML (1ª Versão) aquele que foi obtido pela script omnimark rtf2xml. Pretende-se que o documento XML (2ª Versão) seja derivado do anterior por enriquecimento em termos de anotações. Procedemos a tal utilizando scripts XSL cart1TOcart2.xsl, inv1TOinv2.xsl.
Com este processo obtivemos os documentos, carta2FASE.xml, inventario2FASE.xml com uma estrutura ja próxima daquela imposta pelo DTD
Dado o elevado custo da anotação automatizada de certa informação (nomes, lugares, datas, etc.) , tivemos ainda que sujeitar o documento a uma fase de inserção de tags manual, onde procedemos à anotação mais adequada em cada caso.

Por esta altura, e dado que ambos os documentos já estavam totalmente de acordo com o DTD, reunimo-los num mesmo ficheiro, documento.xml
A fase de transformação do documento XML para HTML foi feita utilizando XSL. Para isso, fizémos uma script que para cada tag XML dá origem a código HTML que apresenta a informação de uma forma adequada à sua visualização num browser. Decidimos utilizar frames, pois pensamos que neste caso ajudam a estruturar a informação e a facilitar o seu acesso. Fizemos duas frames: uma com um índice que permite a procura rápida de uma determinada parte do documento, outra com o documento propriamente dito.
As frames foram geradas automaticamente utilizando para tal o XT. O XT para além de ser um poderoso processador XML e XSL permite-nos a partir de um ficheiro único, criar vários ficheiros de output.
O código completo pode ser encontrado no ficheiro documento.xsl
As restantes tags XML não ofereceram qualquer dificuldade, pois deram origem a código HTML simples. Utilizámos CSS1 para garantirmos que a formatação é coerente nas 2 frames e para não termos de repetir o código de formatação dentro do mesmo documento. Resolvemos escolher cores diferentes para marcar os nomes, locais e datas, tornando mais fácil para o utilizador uma procura dos mesmos.
Como resultado final da mesma stylesheet, obtivemos o ficheiro projecto.html, para além de acerca.html, index.html, capa.html, carta.html e inventario.html.
O objectivo do projecto foi alcançado de uma forma incremental, necessitando de reajustes conforme as necessidades que a correcta representação do documento ia exigindo. As diferentes fases aqui apresentadas foram analisadas pormenorizadamente, sendo concluídas com o que considerámos ser o mais adequado mediante as condicionantes encontradas.
Tendo cumprido o objectivo pretendido sugerimos, como trabalho futuro:
DTD do documento: documentoDTD.dtd
Schema do relatório: relatorio.xsd
Documento em formato XML: documento.xml
Relatório em formato XML: relatorio.xml
StyleSheets CSS do documento: style.css index.css
StyleSheet CSS do relatório: relatorio.css
Script XSL para geração HTML do documento: documento.xsl
Script XSL para geração HTML do relatório: relatorio.xsl
Os ficheiros gerados em fases intermédias do projecto não se encontram aqui listados.