Um documento
eXtensible Markup Language (
XML) representa uma forma simples de armazenamento de dados que podem ser lidos por diversos
programas.
Normalmente, os dados armazenados encontram-se organizados por estruturas específicas
que devem prever quais os elementos presentes no documento, o tipo de dados do conteúdo
presente nas mesmas e a ordem em que estes podem aparecer, entre outros.
Assim, estas estruturas são organizadas de forma hierárquica com o objetivo de
facilitar a interpretação do seu conteúdo.
Desta forma, o
XML apresenta diversas marcas de formatação que traduzem as diferentes partes do arquivo,
descrevendo o que cada conjunto de dados representa, possibilitando um tratamento
muito fácil da informação.
[1]
A linguagem de
XML Schema foi desenvolvida com o objetivo de auxiliar os documentos
XML , ou seja, com o objetivo de tornar uma linguagem apropriada para ser utilizada na
definição dos esquemas dos documentos
XML .
Esta linguagem possui uma vasta hierarquia de tipo de dados e também possui um
maior controlo sobe o número de ocorrências de um determinado elemento.
[1]
O XML Schema define diversos tipos de dados, nomeadamente:
- Elementos que podem existir no documento;
- Atributos que podem existir no documento;
- As relações elemento-filho de um elemento;
- Caracterização do elemento.
XSL (
eXtensible Stylesheet Language) inclui um conjunto de especificações que definem a transformação e apresentação
de documentos XML.
A partir desta linguagem padrão, surgem outros conceitos, com distintas funcionalidades,
como é o caso do XSLT (
XSL Transformations),
do XPath (
XML Path Language) e do XSL-FO (
XSL Formatting Objects), que será de seguida analisado.
[2]
O primeiro trata-se de uma linguagem responsável pela transformação do XML num
documento de outro tipo - HTML, enquanto que o XPath consiste numa linguagem
de endereçamento utilizada pelo XSLT para aceder a partes de um documento XML,
interpretando-o como uma árvore documental abstrata (ADA).
[2]
XSL-FO (
XSL Formatting Objects) é considerada uma linguagem de marcação que permite formatar dados de um XML, especificando
detalhadamente
a paginação, o layout e o estilo a serem aplicados ao conteúdo. Trata-se de um
vocabulário que especifica a semântica de formatação, um conjunto
de ferramentas que descreve a apresentação do conteúdo XML.
[3]
Este tipo de formato apresenta quatro campos principais: as
regiões, que são o nível mais alto da hierarquia e contêm o cabeçalho,
texto e rodapé; os
blocos, que definem um bloco de texto como um parágrafo;
linhas, que representam cada linha de texto num parágrafo;
e as
entre-linhas, como é o caso das referências ou uma equação matemática, que são apenas partes de
uma linha.
[4]
A partir de um processador FLOP (
Flow Objects Processor), este tipo de formato é capaz de gerar um documento PDF (
Portable Document Format).
[4]
HTML (
HyperText Markup Language) é uma linguagem de marcação usada para definir a estrutura de uma página web, permitindo
especificar o modo como
o seu conteúdo deve ser reconhecido.Esta linguagem é constituída por elementos
que incluem diferentes partes do texto, e que são responsáveis por
atribuir um determinado significado à porção selecionada (parágrafo, tabela,
lista), estruturar o documento em secções lógicas (cabeçalho,
menu de navegação, colunas) e adicionar conteúdo ao documento (imagens, vídeos).
[5]
Uma página HTML, tal como se pode ver no exemplo da Figura
1 , apresenta na sua estrutura básica, os elementos:
- html, que é conhecido como o elemento raiz e que envolve todo o conteúdo da página;
- head que pode incluir palavras-chave, declarações que definem o conjunto de carateres
a usar no
documento (meta charset), o título da página que aparece na barra do browser (title) ou CSS para modelar o conteúdo;
- body, que envolve todo o conteúdo que se deseja mostrar na página web.

Figura 1: Estrutura de um documento HTML.
Numa primeira instância, procedeu-se à análise do livro de recortes disponibilizado,
com o objetivo de realizar o levantamento dos elementos presentes no mesmo.
Assim, depois de percecionada a estrutura do documento apresentado, começou-se
por elaborar um schema que fosse capaz de o caracterizar.
Esta etapa definição do schema é extremamente importante, uma vez que uma boa
definição do mesmo facilitará os processos que se seguem,
nomeadamente, a criação das stylesheets.
Deste modo, definiu-se como elemento principal o elemento
livro que é constituído por uma sequência de dois elementos: o
meta e o
conteúdo, tal como se pode observar na Figura
2.
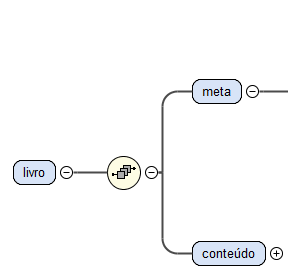
Figura 2: Estrutura do elemento livro.
O elemento
meta, que tem como objetivo a representação da meta-informação do livro, é composto por
uma sequência dos elementos
antetítulo,
título,
subtítulo,
ano e
imagem.
Na Figura
3 encontra-se representada a estrutura do elemento
meta e é possível observar que todos os elementos supracitados, exceto o elemento
imagem, são do tipo string.
O elemento
imagem contém um atributo que funciona como um identificador da mesma.
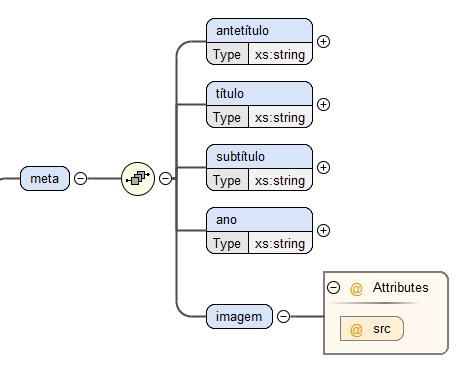
Figura 3: Estrutura do elemento meta.
O conteúdo inclui todas as publicações, que podem ser caraterizadas pela identificação
da imprensa, pela data e local onde foi publicada e pelos recortes,
que vão incluir o texto da notícia e a imagem do recorte.
Deste modo, o elemento
conteúdo será composto por uma sequência de um ou mais elementos
publicação, que por sua vez,
são constituídos por uma outra sequência de elementos
media,
data e
local, de caráter opcional, e
recortes, obrigatório.
Tal como se pode verificar na Figura
4, todos os elementos pertencentes a
publicação são do tipo
string, excetuando o elemento
recortes
que se trata de um
container, por incluir uma sequência de outros elementos.
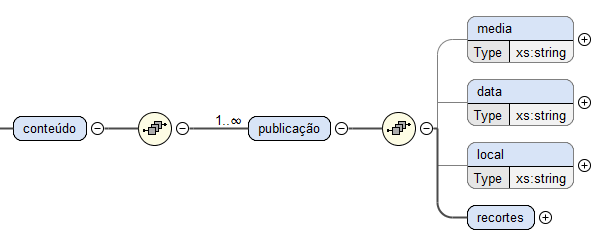
Figura 4: Estrutura do elemento conteúdo.
O elemento
recortes é, então, definido como uma sequência de um ou mais recortes, sendo que cada recorte
também é caracterizado como uma
sequência de um
título, um
subtítulo,
um autor, uma
figuraecorte e um
corpo, tal como se pode verificar na Figura
5.
Os elementos
título,
subtítulo e
autor são do tipo string e são de carácter opcional, ou seja, podem ser ou não definidos.
Por outro lado, os elementos
figurarecorte e
corpo são considerados
containers.
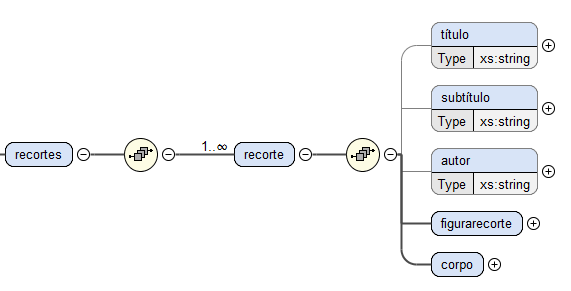
Figura 5: Estrututra do elemento recortes.
O elemento figurarecorte contém um atributo obrigatório para que as figuras dos recortes possam ser devidamente
identificadas.
Para além disto, este elemento é composto pela sequência da imagem e legenda,
identificadas, respetivamente, pelos elementos imgrecorte e legenda.
O primeiro elemento inclui obrigatoriamente, um atributo que indica a localização
da imagem, enquanto que o segundo, uma vez que é do tipo parágrafo, está
definido no Complex Type Tparágrafo .
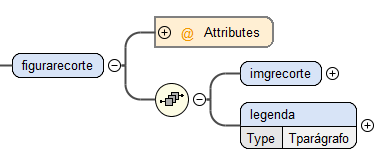
Figura 6: Estrutura do elemento figurarecorte.
O corpo de um recorte pode ser apresentado de duas formas distintas: em texto
corrido ou em estrofes. Desta forma, tal como se pode visualizar na
Figura
7, o corpo é definido como uma ou mais escolhas entre um parágrafo ou uma estrofe.
O parágrafo é caracterizado como um
Complex Type designado por
Tparágrafo que irá ser, seguidamente, explicado.
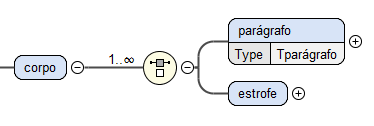
Figura 7: Estrutura do elemento corpo.
Tal como se pode verificar na Figura
8, uma estrofe é composta por uma sequência de um ou mais versos, sendo que cada verso
é definido como um
Tparágrafo.
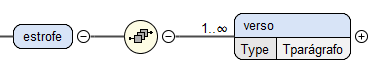
Figura 8: Estrutura do elemento estrofe.
Analisando a Figura
9, é possível inferir que o elemento
Tparágrado é caracterizado como conteúdo misto, ou seja,
pode apresentar elementos de tipos distintos.
Assim, este pode ser apresentar conteúdo em texto, negrito, itálico ou apresentar
informação relativa a nomes, localizações e datas.
O elemento negrito e o elemento itálico apresentam uma particularidade, visto que são definidos como uma escolha de zero
ou mais
ocorrências de itálico e negrito, respetivamente.
Esta caracterização possibilita a existência de elementos que se encontrem simultaneamente
em negrito e em itálico.
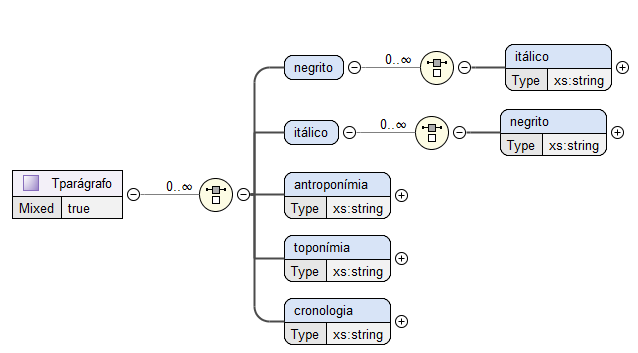
Figura 9: Estrutura do elemento Tparágrafo.
4. Stylesheet para a geração do HTML
No sentido de gerar uma página HTML devidamente formatada com o conteúdo disponibilizado no documento XML, que foi gerado a partir
do XML Schema apresentado anteriormente, foi necessário desenvolver uma stylesheet.
Deste modo, estabeleceu-se que o output da stylesheet desenvolvida é um ficheiro HTML.
Na stylesheet desenvolvida para o efeito começou-se por gerar uma página individual inicial denominada
“index” que é constituída pelos elementos
head e body.
Observando a Figura
10 é possível visualizar detalhadamente o elemento
head da página index, onde foram definidas algumas
formatações iniciais para a página gerada, tais como, as margens, o título e o
parágrafo.
Para tal, foi necessário importar o modelo CSS com o objetivo de melhorar o aspeto
visual dos componentes adicionados à página inicial.

Figura 10: Elemento head da página HTML a gerar definido no documento XSL.
No elemento
body da página inicial, que se encontra representado na Figura
11, foi criada uma
<div> que
tem como objetivo a seleção da informação da capa do livro, ou seja, da imagem,
do antetítulo, do título, do subtítulo e da data.
Seguidamente, foi definido um botão que, quando selecionado, redireciona para
a página denominada
indice.

Figura 11: Elemento body da página HTML a gerar definido no documento XSL.
A página individual
indice, tal como a página inicial, é constituída pelos elementos
head e
body, como representado na Figura
12.
No elemento
head é inserido o título da página enquanto que no
body, inicialmente, é definida uma barra de navegação que permite o redireccionamento
para a página inicial e para a primeira publicação do livro.
Recorrendo a um
<ul> é definida a lista que vai ser contemplada no índice, sendo que cada publicação é
representada através do nome da imprensa, da data e do local onde foi efetuada.

Figura 12: Estruturação da página indice em XSL.
Com o objetivo de representar as publicações indicadas no livro considerado criou-se
um template para as mesmas.
Esse template, tal como os outros templates definidos, é constituído pelos elementos
head e body.
Observando a Figura
13 é possível inferir que o
body de uma publicação é composto por duas
<div>.
A primeira tem como objetivo a inserção de uma barra de navegação que é composta
por quatro âncoras, sendo que cada uma remete para a publicação anterior, para a página
inicial, para o índice e para a publicação seguinte, respetivamente.
Num momento inicial, a segunda
<div> verifica a existência dos dados relativos ao nome da imprensa, à data e ao local
da publicação considerada. Caso estes elementos se verifiquem, são selecionados e
impressos na página da publicação. De seguida, é aplicado o template gerado para cada
recorte dessa mesma publicação.

Figura 13: Estruturação do body de uma publicação em XSL.
Foi criado o
template recorte, tal como se pode ver na Figura
14, com o objetivo de definir o aspeto visual do
mesmo na página html relativa à sua publicação. Assim, foi criada uma tabela que
é constituída por uma linha e duas colunas.
Na primeira coluna dá-se a verificação da existência do título e do subtítulo
do recorte considerado e, caso estes se verifiquem,
são inseridos nesta mesma coluna.
Seguidamente, é aplicado um template que diz respeito ao corpo do recorte.
Por último, verifica-se a existência do nome do autor e, caso exista, é inserido.
Na segunda coluna, é colocada a imagem do recorte em questão e é invocado o template
que caracteriza a sua legenda.

Figura 14: Estruturação do elemento recorte em XSL.
Na Figura
15 encontra-se representado o
template relativo à
legenda de uma figura.
Este template é caracterizado por um parágrafo em que se realiza a contagem de
todas as figuras anteriores e se acrescenta uma unidade a
esse mesmo valor. A soma realizada tem como objetivo a atribuição do número da
legenda da figura considerada.

Figura 15: Estruturação do elemento legenda em XSL
5. Stylesheet para a geração do PDF
A fim de obter o XSLFO para posterior geração de um ficheiro PDF, começou-se por criar uma stylesheet, onde se especificou a estrutura-base de um documento em FO e o respetivo namespace.
O elemento de topo corresponde ao root e os elementos principais são o layout-master-set e o page-sequence.
O layout-master-set é reservado à especificação da geometria de página a adotar para o documento, sendo
as dimensões escolhidas equivalentes a uma página A4 (21 cm x 297 mm). Para além destas,
definiram-se as margens para a região region-body e também a extensão das regiões region-before e region-after.
Cada página segue a formatação indicada no
simple-page-master e o conteúdo é inserido num elemento
page-sequence.
O filho deste elemento é o
flow e nele estão definidos vários blocos,
block, que contêm informação referente à primeira página gerada para o
PDF, como é o caso do antetítulo, título, subtítulo e ano (Figura
16).

Figura 16: Estrutura base do XSLFO.
Gerou-se uma página individual para a imagem de capa e definiu-se como estático
o conteúdo (título, subtítulo e ano) incluindo-o na
region-before.
A imagem de capa é referenciada no elemento
flow, uma vez que se pretende que esta seja inserida no corpo da página,
region-body (Figura
17).

Figura 17: Estruturação da página de capa do XSLFO.
A página referente aos índices foi gerada de forma idêntica à anterior, sendo
usado o mesmo conteúdo estático, conforme ilustrado na Figura
18.

Figura 18: Estruturação da página de índices do XSLFO.
O primeiro índice diz respeito à listagem de publicações, ordenadas por data,
recorrendo ao elemento
list-block para o efeito.
O método
xsl:apply-templates permite aplicar as
templates indicadas com o
mode=”indice”, visitando apenas os elementos
data ainda não visitados.
A primeira
template chamada é indicada na Figura
19.
As imagens inseridas ao longo do documento são também indexadas, chamando as
templates em
mode=”indicefig”.
Na Figura
19 consta essa
template.
Para gerar o índice de publicações, é testada a existência do elementos media, data e local e em caso afirmativo, o valor do elemento data é selecionado e guardado numa variável com o nome d.
Posto isto, é chamada uma nova template, em mode=”ind” na qual é selecionado o valor do elemento media relacionado à data em questão.
Conforme se verifica na Figura
19, o índice é construído à base de elementos
list-block e
list-item.

Figura 19: Estruturação do elemento publicação do índice no XSLFO.
Após seleção do elemento
media, é construída uma hiperligação interna para a publicação correspondente, usando o
elemento
basic-link.
Como cada publicação não tem um ID associado, este é gerado recorrendo à função
generate-id. É ainda feita a correspondência entre o ID da publicação gerado e o número de página
que lhe diz respeito, no
page-number-citation.
Mais uma vez, faz-se uso dos elementos
list-item e
block. A Figura
20 ilustra o código em questão.

Figura 20: Estruturação do elemento media do índice no XSLFO.
Para o índice de figuras usou-se o código presente na Figura
21, que faz
match no elemento
figurarecorte.
De forma a obter uma numeração correta, é feita a contagem dos elementos
figurarecorte precedentes e selecionada a legenda correspondente à figura a ser visitada.
Com o ID referente ao elemento
figurarecorte faz-se o redirecionamento para a respetiva figura e associado o número de página.
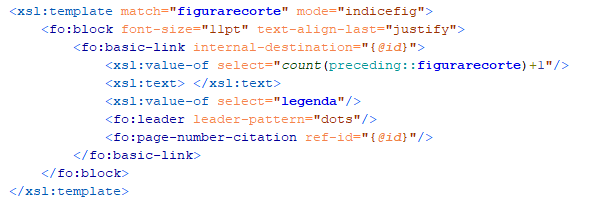
Figura 21: Estruturação do elemento figurarecorte do índice no XSLFO.
Ao selecionar a informação para os índices, deve ser definido um esquema de prioridades,
de forma a eliminar o texto em bruto.
Assim, definiram-se mais duas templates com prioridade “-1” e que selecionam todos
os nodos de texto não chamados, ocultando-os (Figura
22).

Figura 22: Estruturação dos elementos de texto do índice no XSLFO.
As páginas referentes a cada publicação resultam da invocação da
template demonstrada na Figura
23. O formato e as dimensões correspondem às já definidas nas páginas anteriores.
O cabeçalho, definido na seção static-content, contém informações sobre a publicação em questão, como por exemplo, a imprensa,
data e o local de publicação ou o título e autor.
É também indicado um rodapé, com conteúdo estático, onde consta, unicamente, o
número de página.
Com elemento flow são incluídas as informações específicas da página na region-body e aplicadas as templates referentes ao elemento recorte dessa publicação.

Figura 23: Estruturação do elemento publicação no XSLFO.
A
template invocada na Fig
23 é ilustrada na Figura
24.
Para cada elemento recorte, existem blocos com informação sobre o título e subtítulo, caso existam.
O corpo e a figura do recorte estão dispostos numa tabela de uma linha e duas
colunas, tendo-se para isso usado os elementos table, table-row e table-cell.
De forma a aceder ao conteúdo do corpo, é feito um apply-templates. Já para a figura, é selecionado o seu ID e a respetiva imagem, através do atributo
src e elemento external-graphic.
Posto isto, usa-se a expressão apply-templates para invocar a respetiva legenda.

Figura 24: Estruturação do elemento recorte no XSLFO.
A
template que faz
match no elemento
legenda faz a contagem das figuras precedentes, de forma a atribuir o número correto à descrição
da imagem a que se refere.
Posteriormente aplica as
templates dos elementos filhos, conforme indicado na Figura
25.

Figura 25: Estruturação do elemento legenda no XSLFO.
Para as restantes
templates, é usado o método
apply-templates de forma a que possam ser invocados os respetivos elementos filhos.
A Figura
26 representa um excerto do código implementado para algumas destas
templates em particular.

Figura 26: Estruturação de alguns elementos no XSLFO.
Por fim, foram definidos vários
attribute-sets, representados na Figura
27, com o intuito de formatar os campos reservados aos cabeçalhos, rodapé e tabelas.

Figura 27: Estruturação dos attributs-sets no XSLFO.