2. Descrição do Trabalho
Neste capítulo, encontram-se descritas todas as tarefas que foram realizadas de modo a desenvolver a edição em papel, no formato PDF, e a edição em HTML do livro fornecido, recorrendo-se, para tal, ao conjunto de páginas em PDF de recortes de imprensa disponibilizado.
2.1. Especificação do XML Schema e Criação da Instância XML
Num primeiro momento, começou-se por analisar o conjunto de páginas em PDF fornecido de modo a efetuar o planeamento da estrutura e o levantamento de todos os componentes que constituíssem o livro disponibilizado. Uma vez realizada esta análise, passou-se então para a especificação de um XML Schema que tivesse capacidade para descrever a informação contida nos recortes fornecidos.
Deste modo, decidiu-se que o XML Schema deveria ter um elemento raiz denominado "livro", sendo este elemento responsável por conter todo o conteúdo relativo ao livro em questão. Na figura 1, apresenta-se, assim, a estrutura do elemento "livro".
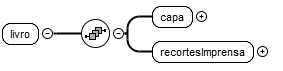
Pela figura 1, verifica-se que o elemento "livro" consiste numa sequência de um elemento "capa" seguido de um elemento "recortesImprensa". Como o nome indica, o elemento "capa" diz respeito à capa do livro e é neste que deve estar inserida toda a informação relativa à capa do livro disponibilizado. Por outro lado, o elemento "recortesImprensa" diz respeito aos recortes de imprensa contidos no livro, pelo que é neste elemento que se devem incluir todos os recortes de imprensa.
Assim sendo, apresenta-se, na figura 2, a estrutura do elemento "capa".
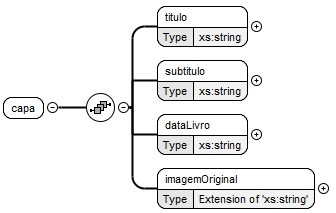
Pela figura 2, verifica-se que o elemento "capa" é constituído por uma sequência de quatro elementos sendo todos eles de caráter obrigatório e do tipo texto (xs:string). Na tabela 1, apresenta-se a definição de cada um destes elementos.
Tabela 1: Definição dos elementos do elemento "capa"
| Elemento | Definição |
| "titulo" | Título do livro; |
| "subtitulo" | Subtítulo do livro; |
| "dataLivro" | Data de criação do livro; |
| "imagemOriginal" | Imagem original contida na capa do livro; |
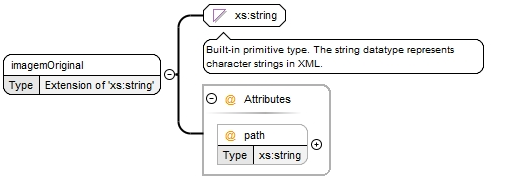
Importa referir que o elemento "imagemOriginal" é igualmente caracterizado pelo atributo "path" do tipo texto, como se pode verificar na figura 3, de modo a ser possível inserir a localização da imagem em questão. Além disso, visto que o elemento "imagemOriginal" é do tipo texto, é ainda possível inserir texto associado à imagem. Esta opção é essencial, uma vez que é este texto que será apresentado caso houver algum erro com a imagem no browser.
Como referido anteriormente, de maneira a que fosse possível representar cada um dos recortes de imprensa contidos no livro, sentiu-se a necessidade de criar o elemento "recortesImprensa". Uma vez que existem vários recortes, foi então necessário definir que o elemento "recortesImprensa" corresponde a uma sequência de um ou mais elementos "recorteImprensa". A estrutura deste último elemento é apresentado na figura 4.
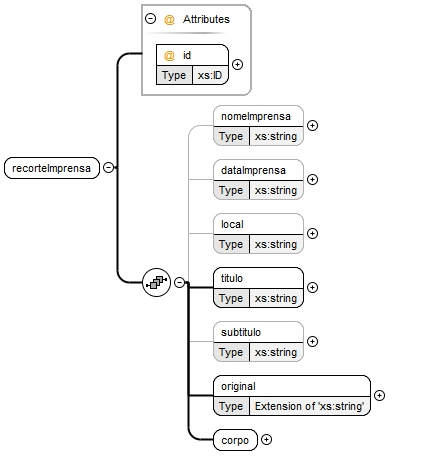
Pela figura 4, constata-se que o elemento "recorteImprensa" foi definido como sendo uma sequência de sete elementos. Além disso, achou-se pertinente caracterizar este elemento por um atributo denominado "id" de caráter obrigatório, de modo a se poder especificar o código de identificação do recorte em questão. Como cada recorte deve possuir uma identificação única, especificou-se este atributo como sendo do tipo xs:ID.
Relativamente aos elementos que definem o elemento "recorteImprensa", apresenta-se, na tabela 2, a definição de cada um deles.
Tabela 2: Definição dos elementos do elemento "recorteImprensa"
| Elemento | Definição |
| "nomeImprensa" | Caso exista, permite indicar o nome da imprensa onde foi publicado o recorte; |
| "dataImprensa" | Caso exista, permite identificar a data de publicação do recorte; |
| "local" | Caso exista, permite identificar o local de publicação do recorte; |
| "titulo" | Permite indicar o título do recorte, sendo este obrigatório; |
| "subtitulo" | Caso exista, permite identificar o subtítulo do recorte; |
| "original" | Permite especificar a imagem original do recorte, sendo obrigatória a sua existência; |
| "corpo" | Onde é colocado o conteúdo do recorte. |
Importa referir que o elemento "original" é semelhante ao elemento "imagemOriginal" referido anteriormente, pelo que apresenta igualmente um atributo "path" onde é especificada a localização da imagem. Além disso, uma vez que é do tipo texto, é ainda possível inserir um texto alternativo associado à imagem em questão.
Numa segunda fase, houve necessidade de definir adequadamente o elemento "corpo", de forma a que fosse possível inserir o conteúdo de cada um dos recortes. Aquando da análise do livro, verificou-se que os recortes podiam ser de dois tipo: uma prosa ou uma poema. Deste modo, o elemento "corpo" foi caracterizado como sendo uma escolha entre um elemento "poema" ou um elemento "prosa", tal como se pode verificar na figura 5.
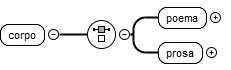
Por sua vez, o elemento "poema" foi definido de forma a ser uma escolha entre os elementos "estrofe", "autor" e "anotacao", devendo um destes surgir pelo menos uma vez, como se apresentado na figura 6.
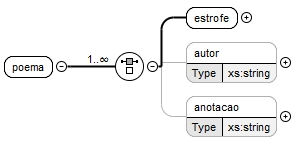
Note-se que tanto o elemento "autor" como o elemento "anotacao" são opcionais, visto que podem ou não aparecer na estrutura do poema, sendo ambos do tipo texto. Relativamente ao elemento "estrofe", este pode ser visto como uma sequência de um ou mais elementos "verso", sendo estes últimos do tipo "Ttexto", como apresentado na figura 7.

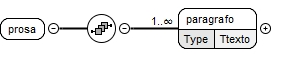
No que diz respeito ao elemento "prosa", este foi definido de forma a que seja uma sequência de um ou mais elementos "paragrafo", sendo estes igualmente do tipo "Ttexto".
Na figura 8, apresenta-se, assim, a estrutura do elemento "prosa".
O tipo "Ttexto" corresponde a um xs:complexType que foi definido globalmente. Para além de ser um tipo complexo, uma vez que inclui um conjunto de elementos, é igualmente do tipo misto, visto que é permitida a existência de texto entre os seus elementos filho.
Na figura 9, encontra-se a estrutura do tipo complexo "Ttexto".
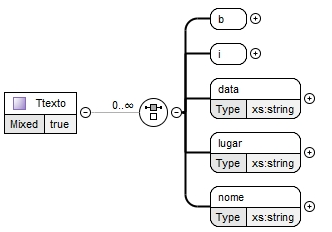
De acordo com a figura 9, tem-se que "Ttexto" é consituido pelos elementos "b", "i", "data", "lugar" e "nome". Os elementos "data", "lugar" e "nome" foram criados de modo a se poder assinalar no texto dos recortes datas, locais geográficos e nomes, respetivamente. Note-se que estes elementos serão essenciais para a geração do índice remissivo na edição em PDF e na edição em HTML. Quantos aos elementos "b" e "i", estes permitem representar componentes a negrito e a itálico, respetivamente. Importa referir que estes últimos elementos são do tipo misto e complexo, sendo que "b" pode conter elementos "i", "data", "lugar" e "nome" e "i" pode conter elementos "b", "data", "lugar" e "nome".
Por fim, uma vez especificado o XML Schema para a publicação final, passou-se à criação da instância XML do mesmo. Este processo foi relativamente simples, consistindo apenas na transcrição do conteúdo presente no livro fornecido para o ficheiro XML de acordo com a estrutura especificada anteriormente.
2.2. Especificação das Stylesheets XSLT
Um dos objetivos deste projeto final consistia na planificação e especificação de duas stylesheets XSLT. A primeira devia ser criada de modo a permitir a geração da publicação final do livro no formato PDF. Em contrapartida, a segunda stylesheet devia ser desenvolvida de forma a possibilitar a geração do livro em formato HTML.
Assim, nesta secção, apresentam-se, resumidamente, as etapas que foram seguidas para a criação destas stylesheets, bem como as decisões que foram tomadas e as dificuldades que se fizeram sentir ao longo do desenvolvimento das mesmas.
2.2.1. Stylesheet XSLT para a Geração da Publicação Final em PDF
Relativamente à stylesheet XSLT para a geração do livro em PDF, começou-se, num primeiro momento, por efetuar um planeamento da estrutura que a edição em papel da publicação final deveria tomar. Assim sendo, achou-se relevante que o livro fosse constituído pelas partes que se apresentam de seguida.
| Capa | Deve conter o título, o subtítulo e a data do livro, bem como a sua imagem original; |
| Índice dos Recortes por Título | Corresponde ao índice dos títulos de todos os recortes de imprensa contidos no livro original; |
| Índice dos Recortes por Imprensa | Corresponde ao índice dos títulos dos recortes por imprensa de publicação; |
| Índice dos Recortes por Data de Publicação | Corresponde ao índice dos títulos dos recortes por data de publicação; |
| Índice dos Recortes por Local de Publicação | Corresponde ao índice dos títulos dos recortes por local de publicação; |
| Páginas de Recortes | Cada recorte de imprensa deve possuir uma página própria na qual é referido o seu título e subtítulo, bem como a imprensa, a data e o local de publicação do mesmo. Para além disso, estas páginas devem conter o texto do respetivo recorte transcrito para o PDF e, por fim, a imagem original do recorte; |
| Índice Remissivo | Corresponde a um índice que contém todos os locais, nomes e datas referidos ao longo do texto dos recortes. |
Seguidamente, tendo-se como ponto de partida a planificação apresentada acima, passou-se então para a especificação da stylesheet propriamente dita.
Ao longo do desenvolvimento desta stylesheet, recorreu-se a um conjunto de funções XPath, de elementos XSLT e de objetos XSLFO, sendo alguns deles mencionados de seguida.
Alguns dos elementos XSLT mais usados foram o xsl:template que permitiu aplicar um conjunto de regras ao nó especificado, o xsl:apply-templates que possibilitou a aplicação de templates ao nodo corrente e aos seus nodos filhos, o xsl:value-of que permitiu extrair o valor do nodo selecionado e o xsl:attribute-set que permitiu criar um conjunto de atributos, sendo estes declarados através do elemento xsl:attribute. Neste caso, criaram-se vários conjuntos de atributos que foram aplicados sobre os títulos, as imagens, os poemas, as prosas, entre outros elementos. Por sua vez, de forma a aplicar os xsl:attribute-set criados sobre os elementos desejados, recorreu-se ao elemento xsl:use-attribute-sets.
O elemento xsl:variable revelou-se também muito importante visto que permitiu declarar variáveis locais. Nesta stylesheet, criaram-se variáveis nos templates associados aos índices dos recortes por imprensa, local e data de publicação, bem como para o índice remissivo. Tal permitiu que fossem selecionados os títulos dos recortes publicados na imprensa, no local ou na data em questão. Quanto ao índice remissivo, o uso deste elemento será explicado mais adiante. Ainda neste contexto, foi usado o elemento xsl:for-each através do qual foi possível efetuar um ciclo em XSLT. Este elemento foi usado para a criação dos índices referidos anteriormente de forma a selecionar, através do seu atributo select, os títulos dos recortes. Já o elemento xsl:sort foi usado para ordenar os valores contidos nos índices.
Por fim, o elemento xsl:if tornou possível efetuar testes condicionais de acordo com o conteúdo contido no ficheiro XML. Similarmente, foi usado o elemento xsl:choose, que recorre aos elementos xsl:when e xsl:otherwise de forma a efetuar um conjunto de testes condicionais. Neste caso, o xsl:choose foi usado nos templates dos índices remissivos de modo a colocar vírgulas entre os números das páginas com exceção do último valor.
Relativamente aos objetos XSLFO, recorreu-se ao fo:list-block e ao fo:table para criar listas e tabelas, respetivamente. Por outro lado, o objeto fo:page-number foi usado para numerar as páginas e o fo:page-number-citation para fazer referência a uma determinada página. Este último objeto foi essencial para colocar a numeração das páginas nos índices.
Além disso, o objeto fo:external-graphic tornou possível a inserção das imagens contidas no livro original para a publicação final em PDF. Já o fo:basic-link foi essencial para criar links nos índices que possibilitam o redirecionamento para a página do recorte em questão.
No que diz respeito às funções XPath usadas, destaca-se o not(), que retorna o valor de verdade contrário à expressão que lhe é passada, sendo que foi usado de forma a evitar a repetição de termos no momento da geração dos índices. Por outro lado, as funções position() e last() revelaram-se essenciais para a enumeração dos números das páginas associada a cada termo contido no índice remissivo. A primeira função permite identificar a posição em que o nodo corrente se encontra na lista percorrida. Já a função last() permite identificar a posição do último nodo. Assim sendo, foi possível colocar vírgulas entre o número das páginas de cada recorte exceto no caso de este ser o último da lista de recortes.
Posto isto, importa referir que, ao longo do desenvolvimento do XSLT, surgiram algumas dificuldades que se referem de seguida.
Tendo em conta as secções que foram referidas acima para a geração da publicação final em PDF, uma das maiores dificuldades que se fez sentir está relacionada com a criação do índice remissivo, uma vez que se achou fundamental que não haja repetições de termos ao longo do índice. Para além disso, tendo em consideração cada termo individualmente, achou-se necessário que não haja repetições na numeração das páginas caso um termo esteja referido mais do que uma vez na mesma página.
Para o primeiro obstáculo, que diz respeito à não repetição de termos ao longo do índice remissivo, foi necessário desenvolver o excerto de código que se apresenta a seguir e que permite colocar numa lista todos os nomes encontrados. Note-se que este excerto diz apenas respeito aos elementos "nome". No entanto, o mesmo raciocínio foi seguido para os elementos "data" e "lugar".
<fo:list-block>
<xsl:apply-templates select="//nome[not(lower-case(.)=preceding::nome/lower-case(.))]"
mode="indice_remissivo_nome">
<xsl:sort select="lower-case(.)" order="ascending" data-type="text"/>
</xsl:apply-templates>
</fo:list-block>
De forma a selecionar todos os elementos "nome" presentes ao longo do documento XML e criar um índice remissivo a partir destes nomes, recorreu-se ao elemento xsl:apply-templates, tendo no seu atributo select uma expressão XPath que permite selecionar todos os elementos "nome" diferentes localizados em qualquer parte do documento. Por outro lado, recorreu-se ao elemento xsl:sort de maneira a efetuar a ordenação, por ordem crescente, de todos os elementos "nome" selecionados anteriormente.
A não repetição dos elementos foi conseguida à custa das funções not() e lower-case(). A função not() aceita uma expressão, calcula o seu valor de verdade e retorna o valor oposto. Assim sendo, esta função permitiu estabelecer que, para cada elemento "nome" selecionado, este não podia ser igual aos outros elementos "nome" previamente selecionados. Assim, selecionou-se o valor referente ao nodo "nome" corrente e, de forma a verificar se este era igual aos nomes anteriormente selecionados, foi necessário usar o axis preceding acompanhado de ::nome, que permitiu efetuar uma travessia a todos os nodos "nome" precedentes. Deste modo, caso o valor do nodo corrente fosse igual a outro previamente visitado, o nome não era selecionado.
Já a função lower-case() aceita uma string, convertendo-a para letras minúsculas. Assim sendo, esta função foi usada de modo a fazer com que a seleção dos elementos "nome" não seja case-sensitive, convertendo-se, assim, todos os elementos "nome" para letras minúsculas. Tal foi feito de modo a que as letras maiúsculas e minúsculas não influenciassem no momento da comparação entre os nomes.
Seguidamente, de modo a solucionar o segundo obstáculo, que diz respeito à não repetição de páginas para um mesmo elemento "nome", concluiu-se que a enumeração dos números das páginas devia ser realizada procurando-se em cada elemento "recorteImprensa" pela existência do nome. Caso o elemento estivesse contido no conteúdo do recorte, a numeração da página do mesmo era colocada no índice associado ao elemento "nome" em questão. Note-se que, antes de adotar esta metodologia, a enumeração das páginas era realizada percorrendo-se cada elemento "nome", pelo que havia repetição das páginas caso um mesmo nome estivesse referido mais do que uma vez numa mesma página.
Para geração do índice remissivo referente aos nomes, começou-se então por criar um template para os elementos "nome", sendo que dentro deste foi declarada uma variável local através do elemento xsl:variable. Tal foi feito de modo a poder guardar o nome para o qual o template estava a ser aplicado em cada momento. Por outro lado, de forma a procurar pelos vários elementos "recorteImprensa" a existência do nome em questão, recorreu-se ao elemento xsl:for-each, tendo no seu atributo select uma expressão XPath que permitiu percorrer cada recorte que tinha no seu elemento "corpo" algum nodo "nome" igual ao valor do nome contido na variável local anteriormente declarada. Desta forma, foi possível obter todos os nodos "recorteImprensa" que tivessem este nome, sendo, posteriormente, efetuada a enumeração das páginas associadas a estes recortes.
Importa referir que o mesmo mecanismo foi usado para gerar o índice remissivo referente aos elementos "data" e "lugar".
Por fim, uma vez ultrapassadas as dificuldades mencionadas e especificada a stylesheet XSLT, gerou-se o seu respetivo ficheiro XSLFO, tendo-se obtido, por meio de um cenário de transformação, o ficheiro PDF da publicação final.
2.2.2. Stylesheet XSLT para a Geração da Publicação Final em HTML
No que toca à stylesheet XSLT para a geração do livro em HTML, houve a necessidade de, primeiramente, delinear uma estrutura para este documento. Decidiu-se então que a publicação final em HTML deveria tomar a forma de um website, sendo que as várias partes constituintes do documento se encontram dividas em várias páginas HTML. Desta forma, foi criada a página index.html, que é relativa à capa do livro. Foi também definida a página toc.html, que apresenta os vários índices que remetem para todo o conteúdo do livro e apresenta também um botão que redireciona para a página relativa ao índice remissivo. Por sua vez, a página ir.html apresenta o índice remissivo e, por fim, foram ainda geradas várias páginas recorteX.html, sendo relativas a cada um dos recortes de imprensa do livro. De seguida, é descrita a estrutura das várias páginas.
| Capa | Apresenta o título e o subtítulo do livro, bem como a data do mesmo e a respetiva imagem. Contém ainda um botão que redireciona para a página relativa aos índices; |
| Índice dos Recortes por Título | Corresponde ao índice dos títulos de todos os recortes de imprensa do livro; |
| Índice dos Recortes por Data de Publicação | Corresponde ao índice dos títulos dos vários recortes de imprensa constituintes do livro, organizados por data de publicação; |
| Índice dos Recortes por Nome de Imprensa | Corresponde ao índice dos títulos de todos os recortes do livro, organizados por nome de imprensa; |
| Índice dos Recortes por Local de Publicação | Corresponde ao índice dos títulos dos recortes, organizados por local de publicação; |
| Índice Remissivo | Trata-se de um índice que contém todos os nomes, lugares e datas que constam nos textos dos vários recortes. Contém ainda um botão que redireciona para a página relativa aos índices; |
| Páginas de Recortes | Cada uma das referidas páginas corresponde a um determinado recorte de imprensa. Estas páginas são constituídas pelo título e subtítulo do recorte, contendo também o nome da imprensa, a data e o local de publicação. Apresentam também o texto do respetivo recorte, assim como a correspondente imagem. Além disso, contêm uma barra de navegação, que permite avançar para o seguinte recorte, retroceder para o recorte anterior ou voltar para a página relativa aos índices. |
Posteriormente, de modo a implementar a estrutura acima apresentada, foi necessário elaborar a respetiva stylesheet. Para tal, recorreu-se a expressões XPath e a elementos XSLT.
Tal como na edição do livro em PDF, os elementos XSLT mais utilizados foram o xsl:template, o xsl:apply-templates, o xsl:value-of, o xsl:variable, o xsl:sort, o xsl:for-each, o xsl:if e o xsl:choose. Para além destes elementos, importa realçar a utilização do elemento xsl:result-document, sendo que permitiu a geração de várias páginas HTML, nomeadamente para a capa, para os índices relativos ao conteúdo, para o índice remissivo e para cada um dos recortes do livro.
Relativamente às funções XPath, destaca-se a função not() e o axis preceding que, tal como no caso anterior da geração do PDF, pretendiam evitar a repetição de elementos. Também foi relevante a utilização da função count(), cujo objetivo é contar o número de nodos. Juntamente com a função count(), utilizou-se também o axis preceding-sibling, que seleciona todos os nodos irmãos precedentes. Com isto, pretendia-se então contar todos os nodos irmãos precedentes ao nodo corrente, que neste caso era o recorteImprensa, de forma a ser possível atribuir o número correto às páginas relativas aos recortes de imprensa, recorteX.html. Este axis foi novamente usado posteriormente na criação de uma barra de navegação nas páginas relativas aos recortes, de modo a ser possível retroceder para o recorte anterior. Da mesma forma, para ser possível avançar para o recorte seguinte, foi utilizado o axis following-sibling.
Além disso, foi novamente usada a função lower-case, de forma a converter letras maiúsculas em letra minúsculas e permitir a comparação entre determinados elementos do texto. No que diz respeito ao índice remissivo, tal como na edição do livro em PDF, recorreu-se às funções position() e last(), de forma a representar as páginas relativas a cada termo presente nesse índice. Também se usou as funções concat(), upper-case() e substring(), de modo a converter a primeira letra de cada termo presente no índice em letra maiúscula dado que, no texto original, alguns desses termos se apresentavam inteiramente em letra minúscula.
Importa ainda referir que, ao longo do desenvolvimento da edição do livro em HTML, foram sentidas algumas das dificuldades que também se sentiram aquando da edição em PDF, sendo que foram resolvidas de semelhante modo.