myAcademia: um gestor de curriculum académico
UCE30::Engenharia de Linguagens::Processamento Estruturado de Documentos
e
Engenharia Web
José Carlos Ramalho
Historial:
Resumo:
Neste projecto pretende-se criar um gestor de currículos académicos (CVs), que passaremos a designar por myAcademia. O projeto consistirá no desenvolvimento de um sistema de informação que permita gerir os dados curriculares de um docente universitário.
A informação a recolher, armazenar e publicar inclui, além da identificação completa do docente, dados sobre a sua formação, dados caraterizando as várias atividades académicas desenvolvidas e resultados atingidos.
Além de assegurar a persistência dos dados, o sistema deverá ter uma interface Web para gestão das várias componentes (o backend), uma outra interface de exploração que permita a exploração da informação pública por terceiras partes (máquinas ou humanos, o frontend), e uma camada de serviços que permita a sua integração com sistemas de terceiras partes (interoperabilidade).
Índice
- Tarefas genéricas a desenvolver
- Arquitetura do sistema a desenvolver
- SIP e o processo de Ingestão
- AIP e o armazenamento de projectos
- DIP e a disseminação/publicação de conteúdos
- O CV académico
- Implementação
- Resultado final
Tarefas genéricas a desenvolver
[Voltar ao índice]
Para concretizar o trabalho será necessário realizar as seguintes tarefas genéricas:
- Analisar o problema e modelar o sistema (arquitetura e dados);
- Especificar o modelo do Repositório de dados: como é que os dados vão ser armazenados, numa base de dados, em ficheiro, numa solução híbrida? qual a sua estrutura?
- Especificar as operações que se pretendem implementar com o nível de detalhe necessário;
- Implementar ambas as partes;
- Testar carregando o sistema com informação real e operando sobre ela;
- Documentar.
Arquitetura do sistema a desenvolver
[Voltar ao índice]
O myAcademia deverá ser implementado seguindo as orientações do modelo OAIS (figura 1).
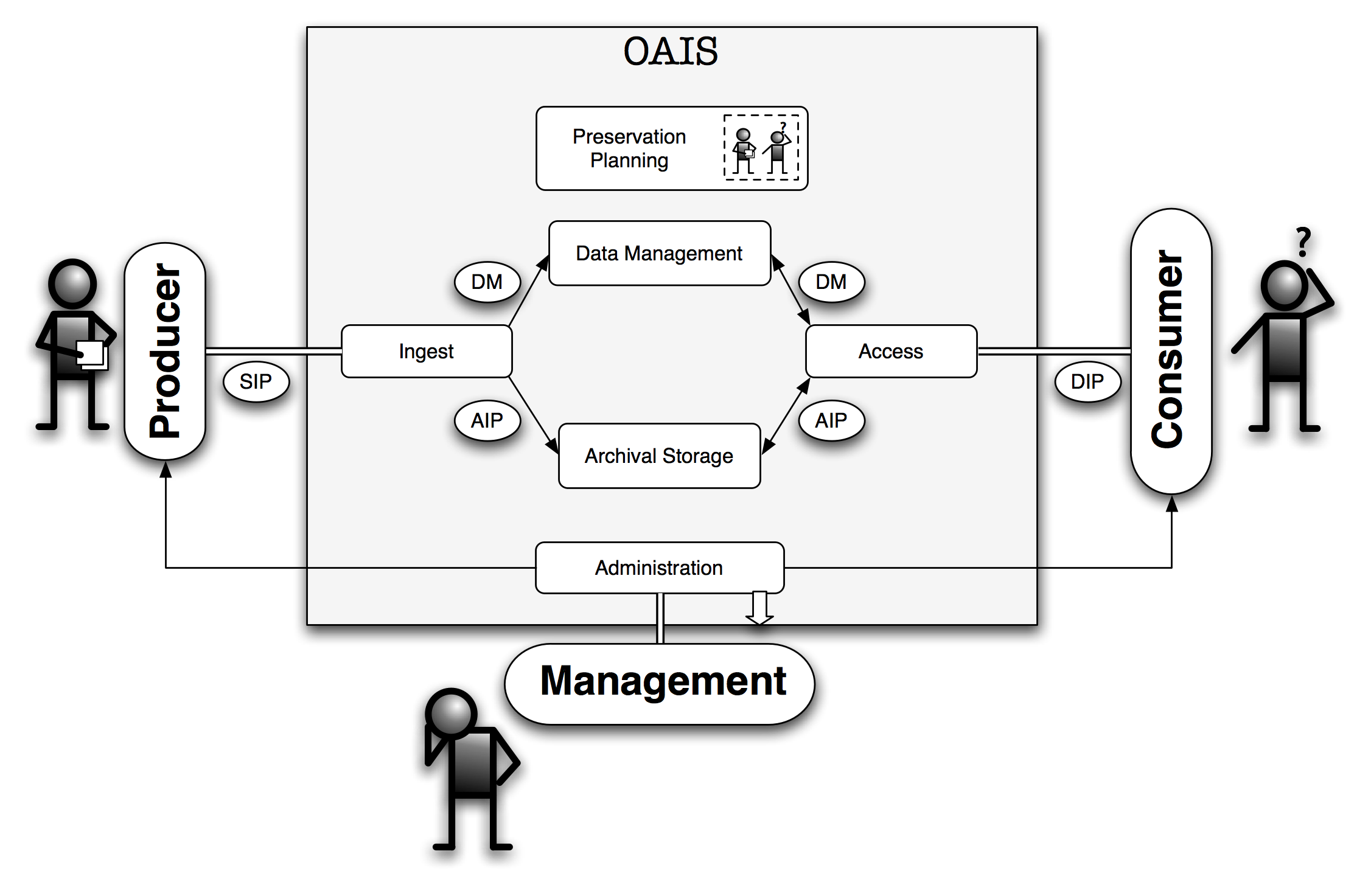
Figura 1: Modelo de referência OAIS
Como se pode ver pela figura, o sistema terá de interagir com três tipos de actores:
- Produtor:
- Corresponde a todos os que produzem conteúdos e os vão depositar no myAcademia. No nosso contexto, os produtores serão os docentes ou o docente, se decidirem que cada instância da aplicação gere apenas um CV;
- Administrador:
- Como o próprio nome indica é alguém com capacidade de mudar e de introduzir alterações ao funcionamento do sistema: ativar um workflow para a submissão de informação, criar utilizadores, alterar perfis de acesso,etc. Este papel será desempenhado por um(s) docente(s);
- Consumidor:
- Corresponde ao futuro utilizador do repositório. Dirigir-se-á a este para consultar e pesquisar informação relativa à informação arquivada. Pode ser qualquer utilizador do universo Web.
Em termos funcionais, o sistema é constituído por 3 megaprocessos:
- Ingestão:
- Processo responsável pela recepção/depósito de materiais a arquivar;
- Administração:
- Processo responsável pela gestão interna do sistema: gestão dos objectos arquivados, gestão de utilizadores, produção de estatísticas, etc.
- Disseminação:
- Processo responsável pela disseminação/distribuição/publicação dos objectos arquivados. Um disseminador tanto pode fornecer ao consumidor final um ZIP com a informação pretendida como pode gerar um website que permita áquele navegar no repositório e visualizar a informação pública.
De acordo com o OAIS, temos três tipos de pacotes de informação a circular no sistema:
- SIP ("Submission Information Package"):
- Pacote que é enviado pelo produtor ao sistema para ser processado e arquivado. A sua estrutura terá de ser especificada no início do projecto.
- AIP ("Archival Information Package"):
- Pacote arquivado, ou seja, um SIP depois de processado e armazenado torna-se num AIP. Este terá uma determinada estrutura que irá depender da forma como será armazenado: base de dados relacional, ficheiro XML, conjunto de pares atributo valor, etc.
- DIP ("Dissemination Information Package"):
- Pacote oferecido ao consumidor. Tanto poderá ser um website a partir do qual aquele consiga navegar nos conteúdos como pode ser um ficheiro ZIP com um conjunto de conteúdos previamente seleccionados.
Nas secções seguintes iremos detalhar um pouco os requisitos pretendidos para o projecto. Como estes estão muito relacionados com os pacotes de informação que circulam no sistema vamos começar por definir o que se pretende para cada um deles.
SIP e o processo de Ingestão
[Voltar ao índice]
Começamos por definir o ponto de entrada no sistema, o SIP e o processo de ingestão que lhe está associado.
Nas primeiras aulas, discutiu-se a estrutura que deveria ter este pacote para um outro projeto, o que resultou na seguinte especificação:
- Um SIP é ficheiro comprimido no formato ZIP;
- O ZIP contem um conjunto de ficheiros onde um deles funciona como manifesto, descrevendo a estrutura e os restantes ficheiros que constituem o pacote;
- Ficou também definido que o manifesto virá sempre num ficheiro de nome sip.xml;
- Todos os outros ficheiros do pacote deverão estar ao nível do manifesto e deverão ser referenciados por este.
O processo de ingestão deverá receber o ficheiro ZIP, validá-lo e armazená-lo.
Validação do SIP
[Voltar ao índice]
A validação do SIP poderá ser constituída pelas seguintes tarefas (outras poderão ser acrescentadas):
- Verificar se o sip.xml existe;
- Verificar se todos os ficheiros referenciados no sip.xml existem no pacote enviado;
- Verificar se os checksum dos ficheiros conferem;
- etc...
Armazenamento do SIP
[Voltar ao índice]
O armazenamento do SIP deverá ser alvo de estudo por parte da equipe de implementação. Solução final poderá ser híbrida: parte da informação numa base de dados relacional, parte da informação no file system numa área gerida pela aplicação, parte da informação em ficheiro XML ou JSON.
Depois do processo de ingestão a informação do SIP foi armazenada e aquele foi convertido num AIP.
AIP e o armazenamento de projectos
[Voltar ao índice]
AIP é a designação que se dá ao objecto intelectual depois deste ter ficado devidamente arquivado.
Neste projecto, o AIP irá corresponder a uma solução híbrida, com uma parte da informação a ser guardada numa base de dados relacional, outra no file system e outra num ficheiro XML.
Os alunos deverão especificar o modelo de entidades e relacionamentos e o esquema da base de dados relacional bem como detalhar a politica de armazenamento que irá ser seguida.
A componente de registo de logs no sistema será guardada num ficheiro XML cuja estrutura e processamento serão abordados durante as aulas.
Os modelos desenvolvidos nas aulas e publicados juntamente com este enunciado são apenas para orientação. Em muitas situações o aluno terá de estender os modelos apresentados. Ou seja, não se limitem ao que foi discutido nas aulas, aproveitem essa informação e tentem ir mais além!
DIP e a disseminação/publicação de conteúdos
[Voltar ao índice]
Um DIP corresponde à forma como se irão disponibilizar os conteúdos armazenados.
Para já, pretende-se que o consumidor/utilizador do sistema tenha à sua disposição um website a partir do qual possa explorar os conteúdos armazenados: listar, consultar a informação relativa a uma categoria, descarregar a informação num formato pré-definido, etc.
Uma outra forma de DIP será a possibilidade de exportação da informação em bloco. Neste caso, o DIP corresponderá a um ficheiro ZIP com uma estrutura semelhante ao SIP.
O CV académico
[Voltar ao índice]
Um CV académico compreende quatro grandes componentes:
- Atividade de Ensino: ensino de vários tipos de cursos aos vários ciclos de ensino superior, publicação de material pedagógico, etc;
- Atividade de Investigação: publicação de trabalhos científicos, projetos de investigação, orientação de trabalhos de pós-graduação, participação em júris, organização de eventos, etc;
- Atividade de Gestão: direção de cursos, presidência de organismos dentro da instituição, etc;
- Atividade de Extensão: prestação de serviços ao exterior, criação de spin-offs, etc.
Para cada um destes componentes deverá ser criado um modelo de dados. O modelo final será a união dos vários submodelos.
Na concepção do projeto, deverá ser refletido que qualquer item de informação pode ser público ou privado e que em qualquer momento o administrador/detentor da informação poderá inverter este estado. Todas as funcionalidade do frontend deverão ter estado em consideração.
Para esclarecimento de dúvidas poderão falar com um docente e consultar a página Web do autor deste enunciado.
Implementação
[Voltar ao índice]
Numa primeira fase, a implementação poderá começar por criar o conjunto de funcionalidades básicas:
- Autenticação
- O myAcademia deverá ter um sistema de autenticação que distinga vários perfis de utilizadores;
- Funcionalidades CRUP
- Cada um dos componentes descritos na secção deverá ter um conjunto base de funcionalidades constituído por:
- Create:
- Cria um registo novo de informação;
- Remove
- Elimina um registo de informação;
- Update
- Altera um registo de informação;
- Lista o(s) registo(s) de informação.
Resultado final
[Voltar ao índice]
O resultado final pretendido é uma aplicação Web que inclua as seguintes funcionalidades (lista incompleta e não exaustiva):
- Gestão de utilizadores e respetivos perfis [backend];
- Autenticação [frontend];
- Gestão de disciplinas lecionadas [backend];
- Gestão de supervisões/orientações de trabalhos [backend];
- Gestão de participações em júris [backend];
- Gestão de publicações [backend];
- Exportação das publicações em formato bibtex [frontend];
- Geração de website dinâmico para exploração de toda a informação pública [frontend];
- Disponibilização das funcionalidades de inserção de informação e de listagem como WebServices, a primeira com autenticação a outra sem [interoperabilidade];
- Resposta a pedidos OAI-pmh [interoperabilidade];