as an Internet Navigation Assistant. SOUR is a system for comparing,
classifying and retrieving information about large software systems.
Figure 1 depicts the overall structure
of the system [16][15][14][18][17][19].
as an Internet Navigation Assistant. SOUR is a system for comparing,
classifying and retrieving information about large software systems.
Figure 1 depicts the overall structure
of the system [16][15][14][18][17][19].
F. Luís Neves
and
José N. Oliveira
Dep. Informática,
Universidade do Minho
4700 Braga,
Portugal
This paper presents a new approach for this problem based on the reuse methodology developed in the SOUR project. Internet links are seen as reusable objects, stored and maintained in a generalize/specialize structure based on a comparison-metrics algorithm. On the implementation side, SOUR is extended by making use of the NETSCAPE's OLE AUTOMATION and DDE interprocess communication mechanisms which allows a third party application to remotely control the NETSCAPE Navigator client.
Navigation across the Internet consists of jumping across a set of links
interactively chosen by the user during a session with an Internet browser.
This may be arduous because of the absence of an effective classification scheme
for the enormous amount of information available
through billions of inter-linked UNIFORM RESOURCE LOCATORs (URLs).
Altogether, this huge world-wide ``information system''
has the structure of an untyped semantic network [5].
The basic idea put forward in this paper is to use the SOUR
software system
as an Internet Navigation Assistant. SOUR is a system for comparing,
classifying and retrieving information about large software systems.
Figure 1 depicts the overall structure
of the system [16][15][14][18][17][19].
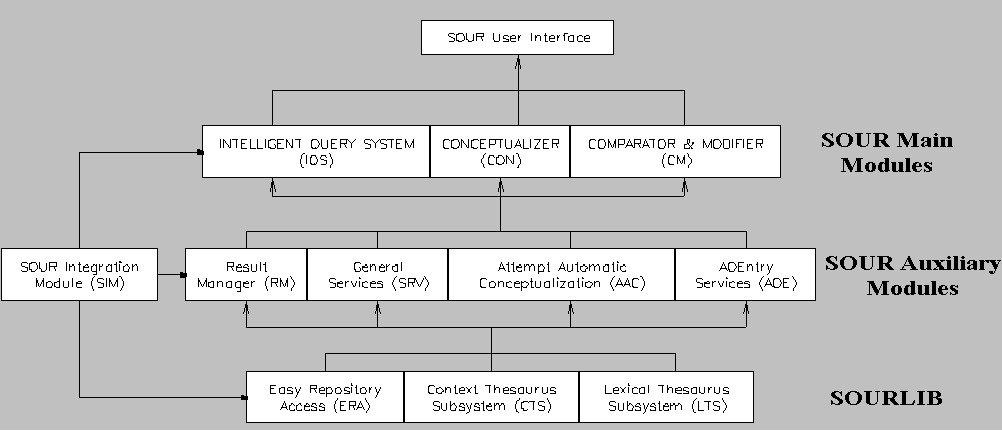
Figure 1: SOUR Overall Architecture
The unit of information in SOUR is the so-called Abstract Object (AO), a notion which combines the enumerative and faceted classification schemes [10][11][12] as an extension of the popular attributive view of objects in the context of a hierarchical semantic network information model.
A crucial decision to make is how to map Internet nodes onto the SOUR
information model.
A URL refers to the format used by World Wide Web (WWW) [21]
documents to locate files on other servers. A URL gives the type of
resource being accessed (e.g., gopher, WAIS), the address of the server
and the path of the file. The format is
scheme://host.domain[:port]/path/filename
where scheme is one of
| file | file on your local system, or a file on an anonymous ftp server |
|---|---|
| http | a resource on a World Wide Web server |
| gopher | a resource on a Gopher server |
| WAIS | a resource on a WAIS server |
| news | an Usenet newsgroup |
| telnet | a connection to a telnet-based service |
The above information scheme can be turned into a SOUR class scheme in a way that will be described in this paper. But a summary of the overall SOUR information model will be presented beforehand.
Information in the SOUR software system [19] is generically recorded in the form of so-called Abstract Objects (AOs) which are independent of their physical support - e.g. text file, POSTSCRIPT file - or location - e.g. pathname.
Abstract objects (AOs) are catalogued in the system's abstract archive according to an adopted standard of classification called conceptualization, which is factored in two layers:
This conceptualization approach is thus a combination of the enumerative and faceted classification schemes [12][11], whereby a physical object (e.g. a piece of C-code) ``becomes'' an AO by attaching to it a profile consisting of the following basic items:
Every AO has a unique identity represented by its AOID (Abstract Object IDentifier). AOIDs are managed by the system and are transparent to the end-user.
It should be noted that two different physical objects may happen to be attached to the same conceptual profile. This leads to a notion of ``conceptualization equivalence'' among objects which has to be managed by the system.
Classnames form a strict hierarchy representing the enumerative side of SOUR's classification scheme. From the user's perspective, the supremum of this hierarchy is AOG (Abstract Object Generic attributes), a class consisting mainly of system controlled attributes such as:
Facets are 6-tuples of terms,
each term instantiating one of the following, predefined
facet types :
Every term instantiating a facet must be present in a subsystem of SOUR called LTS (Lexicon/Thesaurus Subsystem). Terms are related to each other by concepts in a fuzzy way supported by CTS (Context Thesaurus Subsystem), another component of the SOUR architecture [16][15]. Facets may be regarded as ``fuzzy'' attributes. Reference [10] provides a formal discussion about the power of fuzzy classification in practice.
The URL addressing format allows a user to specify any object in the Internet, along with sufficient information to retrieve it. The WWW server is responsible for mapping a supplied URL into an object or responding with an error message [4]. This procedure leads to the notion that every Internet transaction is divided in two distinct phases:
If these two phases are successfully executed it will be possible to access both to the (now valid) URL and the data. The access to the data will have a particular importance in the present study each time the URL identifies an HTML text file. In such case, from the analysis of its contents results that some parts of the text may be used for the conceptualization of the URL.
The following sections will explain in detail how these two entities - the URL and the data which identifies - provide the information that will be attached to an AO.
Assuming the previously (brief) description of an Abstract Object, it is possible to map the URL information scheme described earlier onto a SOUR object by making:
| AO Name | scheme://host.domain[:port]/path/filename |
|---|---|
| AO Address | /path/filename |
| AO Type | filename extension (if any) |
| AO Class | scheme + filename extension (if any) |
As expected, an URL provides, just by itself, the minimal information needed for a successful conceptualization [17]. However, if the URL is a HTML text file then some extra information may be added according to its contents (in a way that will be explained in the sections below), otherwise no more information will be attached.
A specific class hierarchy must be created in order to accommodate the host.domain information which can be used to classify the AO at coarse level. The top of this hierarchy is a class named URL which must have (at least) the following attributes:
| Domain_0 | (e.g www,gopher,ftp,s700) |
|---|---|
| Domain_1 | (e.g. ncsa,telepac,inescn,di) |
| Domain_2 | (e.g. uiuc,inesc,uminho) |
| ... | (...) |
| Domain_n | (e.g. com,pt,org,edu) |
At the same time, URL's subclasses reflect the possible scheme values and even filename extensions. However, if for a given URL the value scheme + filename extension is not the name of an existent (pre-defined) class then only the scheme value is used. The following class hierarchy is a tentative illustration of this idea and specifies some possible subclasses for the HTTP class:
| URL | |||
|---|---|---|---|
| FILE | |||
| HTTP | |||
| HTTPHTML | (Html documents) | ||
| HTTPTXT | (Text documents) | ||
| HTTPPS | (Postscript documents) | ||
| HTTPDOC | (Word documents) | ||
| HTTPTEX | (TeX documents) | ||
| HTTPGIF | (Gif images) | ||
| HTTPZIP | (Zipped files) | ||
| GOPHER | ... | ||
| ... | |||
| WAIS | ... | ||
| ... | |||
| NEWS | ... | ||
| ... | |||
| TELNET | ... | ||
| ... |
Of course, other attributes may be added to the classes reflecting the specific information of their objects.
Faceted classification as proposed in this paper will combine some notions of the software-oriented technology designed for text scheme management such as full text indexing and retrieval, free-text scan, document clustering, unique word and vector-space [3].
The full text's approach generates, in the first place, a list of
strings associated with a document .
Then, at retrieval time ,
a string match will be tried between each string in the index
and a string in the available thesaurus. This strategy is combined
with the unique-word and the vector-space approaches
in order to give more retrieval power to the strings that occur
more often in the text.
Document Clustering attempts to mimic the human thought process by grouping together documents with related ideas, concepts and terminology [8]. This notion is managed by SOUR's COMPARATOR &MODIFIER subsystem [14] as described later in this paper (see section 5).
All these notions can be put together to provide a default facet classification which will be tried by the so-called SOUR's Attempt Automatic Conceptualization (AAC) mechanism [17]. The AAC is applied to the HTML source text of the URL currently being accessed if, of course, the URL identifies a HTML file. The quality of the available CTS/LTS pair is of crucial importance to obtain good results in faceted classification.
For the relevant information to be extracted from the HTML source text, we choose the words that are included in the following HTML structures [6]:
Since we are interested on the classification of documents by their
contents, these must be reflected in the lexical terms available in
the LTS. If, for example, we have a special interest in documents
talking about the WWW, then the LTS shall have terms like
Internet, Information, Web, Hypertext,
Virtual, Browser, CERN, HTML, and so on.
This specialization of lexical terms, which can improve both
the conceptualization and the query mechanism, is supported by
the SOUR's capability of working with several CTS/LTS
repositories .
CTS provides the capability to cope with features of human reasoning such as classifying by analogy and terminological vagueness [10][16][15]. In particular, lexical terms can be connected by conceptual distances interrelating terms (words) according to its contextual meaning. These distances may be regarded as degrees of membership of arcs in a fuzzy graph.
Figure 2 shows a possible set of conceptual relations among the terms described above.

Figure 2: Example of Conceptual Relations
The fuzzy logic technique associated with this information structure provides a method to reduce the so-called precision/recall trade-off. This is one of the methods that has had some success in decreasing the changes of missing important information [3].
The 6-tuples of predefined terms presented earlier (see section 2.1) were designed by Prieto-Diáz for the specific task of software classification. It is an open problem how these can be extended or adapted to so generic information as accessed through any Internet navigation.
The pre-inserted values for each one of these facets will serve as guidelines for document classification. Possible matches among those values and the words extracted from the HTML text reflect part of the so-called AAC mechanism. The others will be described in the sections below.
We now show how the semantic network overall structure of Internet matches with the internal AO-structure of SOUR.
The HTML source text of the URL currently being accessed can also be used
to extract AO link information. Each hyperlink to an external
file
will be identified as an inlink
of the AO that abstracts the current URL.
Possible references include:
Hyperlink, Image and Embedded references become inlinks after the following procedures:
As an example, consider the access to the following address:
http://www.di.uminho.pt/cnw3.html
Directly from the URL it is possible to extract the following AO information:
| AO Name | http://www.di.uminho.pt/cnw3.html |
|---|---|
| AO Address | /cnw3.html |
| AO Type | HTML |
| AO Class | HTTPHTML |
| Domain0 | www |
| Domain1 | di |
| Domain2 | uminho |
| Domain3 | pt |
Now consider that the HTML file identified by the previous URL is the following:
<HTML> <HEAD> <TITLE> WWW National Conference </TITLE> </HEAD> <BODY> <H1> <CENTER> WWW National Conference <P> <IMG ALIGN=MIDDLE SRC="/IMI/imi2-ing-interlace.gif"> <P> Internet Multimedia Information </CENTER> </H1> <H2> <CENTER> July 6-8, 1995 <P> <A HREF="http://www.di.uminho.pt/english-um.html">Minho University</A> <P> <A HREF="http://s700.uminho.pt/braga.html>Braga</A>, <A HREF="http://s700.uminho.pt/homepage-pt.html>Portugal</A> </CENTER> </H2> </BODY> </HTML>
From the analysis of the HTML source text we obtain the following references:
References 1 and 2 will be analyzed in detail in the next section. The other two (references 3 and 4) will originate AOs
| AO Name | http://s700.uminho.pt/braga.html |
|---|---|
| AO Address | /braga.html |
| AO Type | HTML |
| AO Class | HTTPHTML |
| Domain0 | s700 |
| Domain1 | uminho |
| Domain2 | pt |
and
| AO Name | http://s700.uminho.pt/homepage-pt.html |
|---|---|
| AO Address | /homepage-pt.html |
| AO Type | HTML |
| AO Class | HTTPHTML |
| Domain0 | s700 |
| Domain1 | uminho |
| Domain2 | pt |
Finally, these two AOs will produce the inlinks:
which will become part of the conceptualization of the current URL.
Figure 3 shows the result of the conceptualization of the URL ``http://www.di.uminho.pt/cnw3.html''. This figure displays both the links and the comparison relations among AOs.
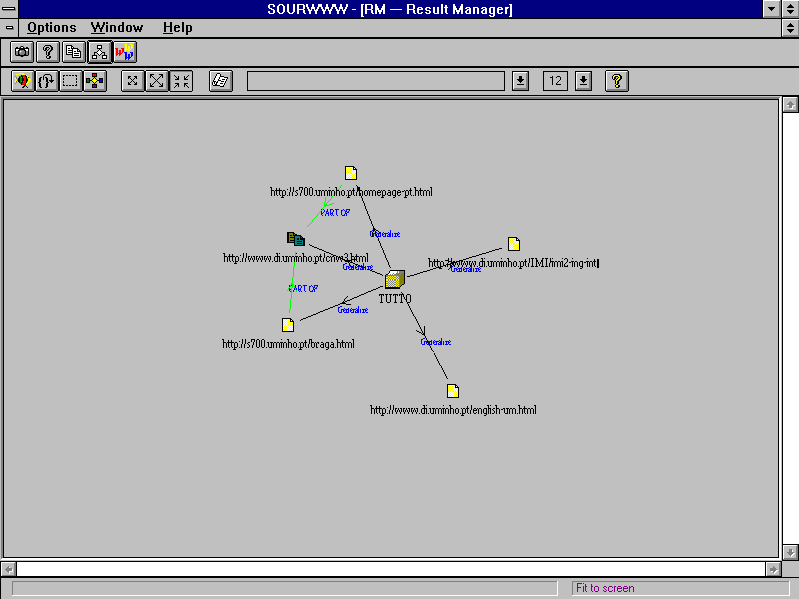
Figure 3: AO Links
In a similar way, the source text of the URL currently being accessed
can also be used to extract AO member information. Each hyperlink
to a local file
will be identified as a member of the AO that maps the current URL.
Possible references include:
All these references will create member links identified by the label ``Member Of''. In the running example above, references 1 and 2 from the previous section,
will produce AOs
| AO Name | http://www.di.uminho.pt/IMI/imi2-ing-interlace.gif |
|---|---|
| AO Address | /IMI/imi2-ing-interlace.gif |
| AO Type | GIF |
| AO Class | HTTPGIF |
| Domain0 | www |
| Domain1 | di |
| Domain2 | uminho |
| Domain3 | pt |
and
| AO Name | http://www.di.uminho.pt/english-um.html |
|---|---|
| AO Address | /english-um.html |
| AO Type | HTML |
| AO Class | HTTPHTML |
| Domain0 | www |
| Domain1 | di |
| Domain2 | uminho |
| Domain3 | pt |
Finally, these two AOs will produce the member links:

which will become part of the conceptualization profile of the current URL. Figure 4 shows the RM's Zoom In graphical functionality [19] operating on URL ``http://www.di.uminho.pt/cnw3.html''.
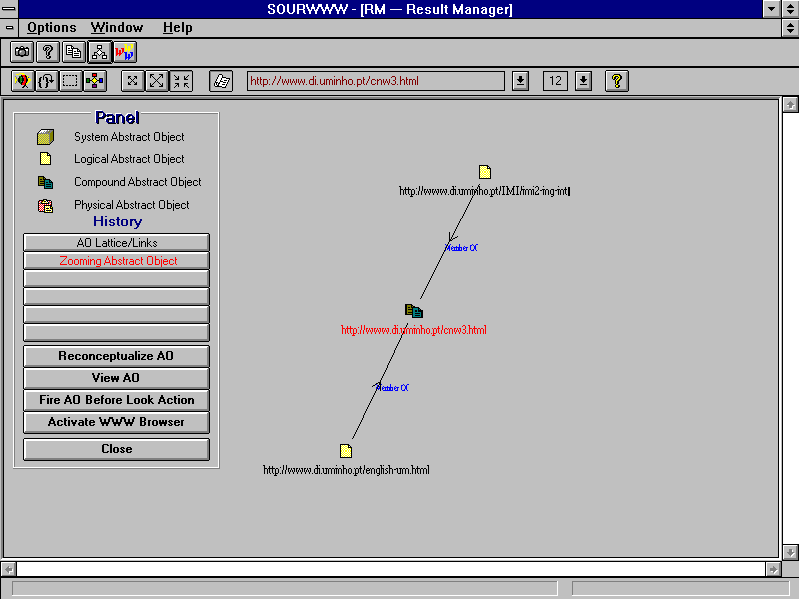
Figure 4: AO Members
The INTELLIGENT QUERY SYSTEM is the SOUR's subsystem intended for consulting SOUR's information [18]. It supports an assisted query mechanism for retrieving information based on standard attribute and ``fuzzy'' query templates. While the former inspects directly the Internet Navigation hypertext structure, the later looks deeper allowing searches based on the contents of the target objects. In the running example of the previous sections, the following query
Get all the URLs stored in Portuguese servers that use the HTTP protocol and which make references to the file ``http://s700.uminho.pt/homepage-pt.html'' (the Portuguese home page).
reflects the linked structure of the resulting URL (see figure 3), while the following one is based on the contents of the referenced data:
Get all the the documents talking about ``WWW'' with fuzzyness level greater or equal to 60%.
This last query uses the facet values of each AO currently stored in the repository and the conceptual relations illustrated in figure 2, in order to find the objects within the specified fuzzyness level.
The SOUR query mechanism combines both the expressive power of the SQL and fuzzy-logic searching techniques. The outcome is something we might call a "fuzzy SQL processor" with a highly assisted, interactively user interface [19].
The notion of ``proximity'', which leads us to the idea of arrangement or grouping, is crucial for the classification problem, in general, and for document organization and retrieval in particular. As documents become more and more the center of computer activity, it will be of a dramatic importance its identification, store, track, retrieve and presentation [13].
The COMPARATOR subsystem of SOUR[14] is encharged of maintaining an ordered structure of AOs which are grouped hierarchically according to a ``proximity'' order defined on the system's standard of conceptualization. It performs the crucial task of comparing Abstract Objects (AOs), while providing a meaningful decision procedure for AO-equivalence. The relevance of COMPARATOR cannot be underestimated - it amounts to the definition of AO-semantics itself, based upon the belief that document semantics can be effectively captured by the adopted attributive model.
The standard attribute-based comparison, at coarse level, is present as a preliminary, less discriminant decision procedure. But with such a procedure the expressive power of the system does not go beyond the conventional, object-oriented information model.
The desired increase in expressive power is achieved at fine level, where object comparison is ``fuzzy'' and is decided according to a metrics or algebra of proximity which computes intersections of the proximity closures of facet values within their hierarchical conceptual graphs. For the technical aspects of this sophisticated tool, see [14] and [10].
The NETSCAPE Client APIs (NCAPIs) are provided as part of version 1.1N release of NETSCAPE. They are designed to allow third party applications to remotely control the NETSCAPE Navigator client [9]. This mechanism includes both the so-called OLE AUTOMATION and DDE Protocol mechanisms.
Wherever interacting with these APIs, SOUR will regard its object repository as stored in a dynamically ``extended file system'' across the Internet. For that, SOUR and NETSCAPE will cooperate based on the client/server technology supported by the DDE implementation of NETSCAPE version 1.1N [2]. In this way, SOUR will manipulate NETSCAPE to execute and/or extract the information of a given URL.
The first step is to gain access to the NETSCAPE's OLE Automation object (the Netscape.Network.1 Automation Object to be more specific [1]). Using this object, SOUR will be able to access network data through the same mechanisms NETSCAPE uses. However, NETSCAPE's OLE AUTOMATION does not provide the functionality necessary to manipulate the NETSCAPE NAVIGATOR user interface. This is possible only by using the DDE protocol which will make SOUR to act simultaneously like a NETSCAPE client and server, as illustrated in figure 5.

Figure 5: DDE Protocol
While acting as a NETSCAPE's client, SOUR uses NETSCAPE
as a displayer for the URLs which have been conceptualized.
When it is working as a NETSCAPE's server, SOUR is notified
every time the loading of a URL occurs .
After the notification, the URL is mapped to a SOUR AO
(see section 3) while the HTML source text
is saved for further analysis
(see the sections 3.3,3.4 and 3.5
earlier in this paper).
After all these steps, the AO information is finally described
in the Conceptualization Batch Language format [17]
and saved into a text file. Finally, whenever SOUR becomes the active
application, it will verify and load all the files created by this process.
Once satisfactorily conceptualized, each URL will be classified
in the system's repository as a conventional SOUR object.
After that, it will be possible to use the
SOUR software system both for have access to its standard functionality
(available in the release  of the system [19]) or to launch
a ``batch'' NETSCAPE navigation session, which is available through a
specially developed capability of SOUR's RM (Result Manager) subsystem.
RM is a generic SOUR service-tool for graphically displaying,
consulting and executing AO's related information which,
in the present context, becomes also a graphical environment
for browsing the Internet linked structure (see figures 3
and 4).
of the system [19]) or to launch
a ``batch'' NETSCAPE navigation session, which is available through a
specially developed capability of SOUR's RM (Result Manager) subsystem.
RM is a generic SOUR service-tool for graphically displaying,
consulting and executing AO's related information which,
in the present context, becomes also a graphical environment
for browsing the Internet linked structure (see figures 3
and 4).
Figure 6 shows the result of activating the NETSCAPE NAVIGATOR for displaying a selected AO. This operation loads the correspondent URL (using the OLE AUTOMATION mechanism) into the current NETSCAPE window.
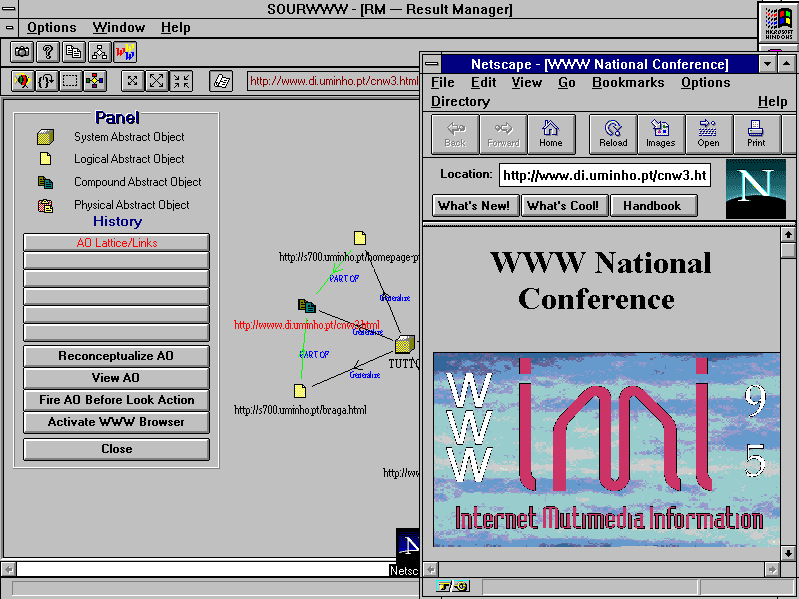
Figure 6: Activating Netscape Browser
This paper presents some modifications and extensions to the current SOUR prototype (running on WINDOWS [19]) in order to make it a useful tool for the classification, storing and retrieval of Internet information.
The key aspects of the SOUR information model reflects the way in which documents are regarded today, no longer just mere files, but rather as books of pointers to objects of several kinds [13]. On the one hand, it can provide some important mechanisms in order to organize and, consequently, make the Internet navigation simpler. On the other hand, as the access to the information becomes easier and powerful, it can act like a personal tool for getting the information directly from the Web and, at the same time, to store and arrange it in the personal workstation into a more human-based organization model.
Among the topics discussed in the paper, probably the most complex is designing a general classification framework for arbitrary documents. However, the approach adopted by SOUR concerning software reuse in particular [11][12], as well as recent studies on fuzzy object-comparison [10] offer good perspectives for the future.
Future work includes the prospect of ``globalizing'' the adopted classification strategy. This means to scale up the approach from personal to world-wide classifiers. Some similarity between AOs and UNIVERSAL RESOURCE CITATIONS (URCs) [22] suggests that the SOUR AO profile-based paradigm can be scaled-up to a world-wide, Internet resource-based ``yellow-page''-like service of bibliographic metadata about WWW documents. Naturally, URCs would have to be extended with fuzzy attributes. But performance feasibility will have to be studied beforehand.
The authors wish to thank all the colleagues in the SOUR consortium (INESC, SYSTENA, SSS and OIS RICERCA) who contributed to the many discussions along the project's lifetime. On the implementation side, comments by Garret Arch Blythe and Steve Caine are gratefully acknowledged.